Hash Table Hypothetical
Moderator: Ras
-
rjgibert
- Posts: 317
- Joined: Mon Jun 26, 2006 9:44 am
Hash Table Hypothetical
If there was an oracle that could tell a program, which positions are the most valuable to hash into the hash table, how much of a benefit would this represent to a program?
-
Dann Corbit
- Posts: 12870
- Joined: Wed Mar 08, 2006 8:57 pm
- Location: Redmond, WA USA
Re: Hash Table Hypothetical
It would know what the perfect PV is and there would be no need for any other part of the chess engine.rjgibert wrote:If there was an oracle that could tell a program, which positions are the most valuable to hash into the hash table, how much of a benefit would this represent to a program?
-
rjgibert
- Posts: 317
- Joined: Mon Jun 26, 2006 9:44 am
Re: Hash Table Hypothetical
You've selected a concept of most valuable that is not useful.
I'll rephrase. How how much of a speedup to the search can one get with an effective way of determining, which hash table entries should be overwritten and which should be kept? Please assume the program still needs to complete what is otherwise a normal search.
I guess what I'm getting at is, if it be fruitful to try to improve the hashing by making it more intelligent or is this simply not worth the effort.
I'll rephrase. How how much of a speedup to the search can one get with an effective way of determining, which hash table entries should be overwritten and which should be kept? Please assume the program still needs to complete what is otherwise a normal search.
I guess what I'm getting at is, if it be fruitful to try to improve the hashing by making it more intelligent or is this simply not worth the effort.
-
Dann Corbit
- Posts: 12870
- Joined: Wed Mar 08, 2006 8:57 pm
- Location: Redmond, WA USA
Re: Hash Table Hypothetical
I guess that it is a function of many things. If you have a very large hash table (or very fast time control), then the frequency of overwrites will be small and so the value of preserving individual entries will be less.rjgibert wrote:You've selected a concept of most valuable that is not useful.
I'll rephrase. How how much of a speedup to the search can one get with an effective way of determining, which hash table entries should be overwritten and which should be kept? Please assume the program still needs to complete what is otherwise a normal search.
I guess what I'm getting at is, if it be fruitful to try to improve the hashing by making it more intelligent or is this simply not worth the effort.
One easy candidate for a garbage entry is "too many chessmen". It would require someplace in the hash table to store the piececount. Since we have to have piececount for our chess programs, the number is sure to be lying around somewhere anyway. If the hash table entry has more chessmen than there are on the board at the current root node, it's definitely worthless now, even if it was a root pv node at one time.
I think that any candidate reason for tossing hash entries must be computable almost instantly. If we slow the hash table down by 5% then the increased hit rate must find enough new entries to speed the entire search operation up by a commensurate amount.
I am guessing that most advanced hash table replacement schemes are going to have a very modest effect on program speed. But I would be interested in any experiments that show otherwise.
-
hgm

- Posts: 28499
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Hash Table Hypothetical
You can typically expect gains like this:
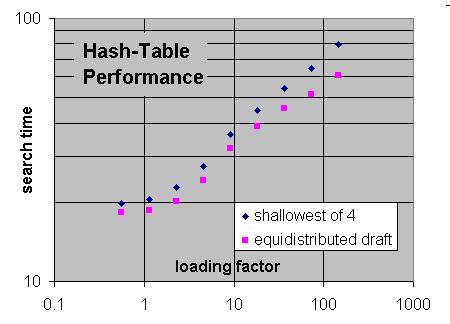
The "shallowest of 4" replacement is what most people use: always replace the entry with the lowest draft of 4 consecutive entries by the new one, if there was a miss.
The "equidistributed draft" is a more advanced replacement scheme.
The "loading factor" is the ratio of the number of nodes in the tree and the size of the hash table. So loading factors smaller than 1 mean that the entire tree fits into the hash table. Under those conditions, it does not matter much what kind of replacement you use, as replacement will hardly occur. But you can see that for large overloading (tree much larger than the table) you can gain some 25% in speed. With current hardware, where you can easily afford a table with 64M entries and you can do 1M nps, overloading would start only at 1 min/move. So you could expect to see differences only at very slow time controls. SMP shifts this a little bit, but we remain far from needing overloads of 100.
Memory is too cheap nowadays! You don't have to worry about using it efficiently. Just waste it...
The "shallowest of 4" replacement is what most people use: always replace the entry with the lowest draft of 4 consecutive entries by the new one, if there was a miss.
The "equidistributed draft" is a more advanced replacement scheme.
The "loading factor" is the ratio of the number of nodes in the tree and the size of the hash table. So loading factors smaller than 1 mean that the entire tree fits into the hash table. Under those conditions, it does not matter much what kind of replacement you use, as replacement will hardly occur. But you can see that for large overloading (tree much larger than the table) you can gain some 25% in speed. With current hardware, where you can easily afford a table with 64M entries and you can do 1M nps, overloading would start only at 1 min/move. So you could expect to see differences only at very slow time controls. SMP shifts this a little bit, but we remain far from needing overloads of 100.
Memory is too cheap nowadays! You don't have to worry about using it efficiently. Just waste it...
-
mjlef
- Posts: 1494
- Joined: Thu Mar 30, 2006 2:08 pm
Re: Hash Table Hypothetical
My guess is a material hash tabel, preloaded with simple stuff like KNvK and KBvP and KNNvK are draws, and KNvKP, etc are likely draws. Programs like ProDeo, Strelka and NOW use a material table for these kinds of things, and it keeps the program from thinking things like KB v K are +3!rjgibert wrote:If there was an oracle that could tell a program, which positions are the most valuable to hash into the hash table, how much of a benefit would this represent to a program?
For the main hash table, you can prefill it at the beginning of the game with positions and scores from previous searches. To do this you have to save root scores, hash key and depth to disk. This allows the program to "learn" from previous games. For example, if at move 15 the program finds it is going to lose a knight no matter what at a 12 ply search, you store the score and depth in this table. Next time you play the same or similar sequence of moves, the search at say move 13 will see the hash entry and replace a search with that entry, and so know earlier on what move leads to that loss, and hopefully avoid it. This is great if people book up against a program, since it can learn to avoid these pitfalls.
Mark
-
bob
- Posts: 20943
- Joined: Mon Feb 27, 2006 7:30 pm
- Location: Birmingham, AL
Re: Hash Table Hypothetical
It would primarily depend on the overwrite rate. In Crafty, where I don't hash in the q-search, a reasonable table size produces a minimal overwrite rate. For example, on a machine with 16gb of ram, giving 12gb of hash, that produces one billion table entries. I am not going to search one billion non-qsearch nodes or more to start overwriting entries, in any reasonable time control... With a low overwrite node, the effect of a "perfect replacement strategy" would be minimal.rjgibert wrote:If there was an oracle that could tell a program, which positions are the most valuable to hash into the hash table, how much of a benefit would this represent to a program?
One interesting way to look at this is to find a copy of the Hennesy-Patterson architecture book. In there, when looking at various things like reorder buffer size, etc, they answer exactly that same question when applied to architecture issues. For example, how well would a processor perform given (a) unlimited reorder buffer size (for out of order instruction queueing); (b) perfect branch prediction; (c) unlimited number of instruction pipelines; etc. The answers are pretty amazing in that the effect is not very significant. If N is optimal or near-optimal, 2N is not going to get much as you can't go beyond perfect... Ditto for 4N, etc...