When implementing hash tables in the days that memory was limited (1 Mb if you were rich) I set-up my hash table data structure as follows:
- One hash table for odd plies
- One hash table for even plies
And where ever possible make the odd ply HT twice as big as the even ply HT because that one is accessed the most due to the AB behaviour. And it also worked great in case of a full HT. Anno 2012 I wonder if that's still the case.
Anyone using a somewhat similar system ?
Hash table division
Moderator: Ras
-
hgm

- Posts: 28499
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Hash table division
For me 'equidistributed draft' tested as best replacement scheme. This effectively divides up the hash table in equal sections for each ply. (But in a dynamic way, because you don't know in advance how deep the search will be.)
The point is that deep drafts will save you an enormous amount of work on a single hit, but on the other hand have to be kept around excessively long before you get such a hit. (Because moves close to the root change only slowly, so it takes a long time before you construct the transposition there that will reach it again.) So you might have benefitted more from the table entry by storing 100,000 different shallow drafts in there, giving you 50,000 hits that saved you only a little amount of work.
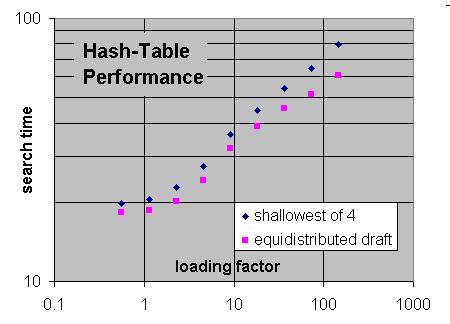
The point is that deep drafts will save you an enormous amount of work on a single hit, but on the other hand have to be kept around excessively long before you get such a hit. (Because moves close to the root change only slowly, so it takes a long time before you construct the transposition there that will reach it again.) So you might have benefitted more from the table entry by storing 100,000 different shallow drafts in there, giving you 50,000 hits that saved you only a little amount of work.
-
sje

- Posts: 4675
- Joined: Mon Mar 13, 2006 7:43 pm
Re: Hash table division
Symbolic has always done this with one table for WTM and one for BTM.
-
bob
- Posts: 20943
- Joined: Mon Feb 27, 2006 7:30 pm
- Location: Birmingham, AL
Re: Hash table division
I simply xor a STM value. I'm not sure I'd want two different tables. What happens in positions where one side has lots of mobility and one side is very restricted? One table fills up, the other is barely used...sje wrote:Symbolic has always done this with one table for WTM and one for BTM.
I've never thought, in any scenario, that two separate tables works, unless you talk about two tables in the Belle sense, where one is a depth-preferred replacement strategy while the other is an always-store table. But for Belle, both store both WTM/BTM entries, so there is no "side-to-move boundary".
-
bob
- Posts: 20943
- Joined: Mon Feb 27, 2006 7:30 pm
- Location: Birmingham, AL
Re: Hash table division
You realize that if you do an even-ply search, 1/2 of the hash stores are going to be from that last layer of even-ply searches??? That is, for every depth N-1 node where N-1 is odd, you will always see a depth N search (and probe).Rebel wrote:When implementing hash tables in the days that memory was limited (1 Mb if you were rich) I set-up my hash table data structure as follows:
- One hash table for odd plies
- One hash table for even plies
And where ever possible make the odd ply HT twice as big as the even ply HT because that one is accessed the most due to the AB behaviour. And it also worked great in case of a full HT. Anno 2012 I wonder if that's still the case.
Anyone using a somewhat similar system ?
I don't see why this makes any sense at all...
-
BubbaTough
- Posts: 1154
- Joined: Fri Jun 23, 2006 5:18 am
Re: Hash table division
Given the variety in search depths that goes on in current programs, I would think it would be pretty hard to guess how things will work...real data seems necessary with funny effects from LMR, null move, and so on.bob wrote:You realize that if you do an even-ply search, 1/2 of the hash stores are going to be from that last layer of even-ply searches??? That is, for every depth N-1 node where N-1 is odd, you will always see a depth N search (and probe).Rebel wrote:When implementing hash tables in the days that memory was limited (1 Mb if you were rich) I set-up my hash table data structure as follows:
- One hash table for odd plies
- One hash table for even plies
And where ever possible make the odd ply HT twice as big as the even ply HT because that one is accessed the most due to the AB behaviour. And it also worked great in case of a full HT. Anno 2012 I wonder if that's still the case.
Anyone using a somewhat similar system ?
I don't see why this makes any sense at all...
-Sam
-
diep
- Posts: 1822
- Joined: Thu Mar 09, 2006 11:54 pm
- Location: The Netherlands
Re: Hash table division
hi Ed, if that's what you're doing, indeed this century there is better systems, though what most don't realize is that the hashtable, total unmissable for todays software, or they get total crushed, is a lot less relevant for Rebel, thanks to its very unique search.Rebel wrote:When implementing hash tables in the days that memory was limited (1 Mb if you were rich) I set-up my hash table data structure as follows:
- One hash table for odd plies
- One hash table for even plies
And where ever possible make the odd ply HT twice as big as the even ply HT because that one is accessed the most due to the AB behaviour. And it also worked great in case of a full HT. Anno 2012 I wonder if that's still the case.
Anyone using a somewhat similar system ?
What started to work far superior for programs start this century is the system as i posted it end 90s, and repeated so start 21th century.
You have 1 big hashtable which you clean at startup or when receiving the openingsposition (or newgame) and then calculate using Zobrist the position in the hashtable. There you try 4 entries in a row and overwrite always the position with the lowest storevalue. The storevalue simply is a few bits, say a bit or 8, though you can risk less, which is the search depth added with the movenumber in the game.
Note i describe 4 entries in a row here. Back then i did do 8 and might go back to trying 8 once again. We call that in that case 8 probes. So default i'm doing 4 probes.
Most effective is moving from 1 to 2 probes.
The effect from 2 to 4 is still significant improving the search quality.
From 4 to 8 obviously only is interesting when the loading factor is over 0.5 or even far above that.
Loading factor you can of course calculate in 2 manners; just chaining will slightly influence the real loading factor to be slightly lower than the theoretic guessed loading factor, which is not a big deal.
Note that Diep also stores qsearch into hashtable, not all engine might have enough system time to do that, so the above probe numbers and decision taking values might be different from program to program there.
AFAIK i was the first one really using 4 sequential or more probes. Bob described in 90s doing 8 random probes (to avoid chaining), but of course at modern memory systems using more than 1 table is pretty slow and/or gives some overhead.
The hashtable though it works simple at cpu's, is so total crucial for todays elorating, without maybe even some world top players win blindfolded from what are top engines now.
Note that it is possible to always keep improving the working of the hashtable, it's such a crucial table now, even reduction decisions get taken based upon whether you have the hash entry or not. Also for cutnodes it's total crucial to have that best move in hashtable, otherwise you might reduce the best move in this position with some increased chance, directly losing elorating statistically for about every engine.
I'm sure that the hashtable codes in 20 years from now are doing a lot more than today. It just keeps getting more complex, not simpler.
-
diep
- Posts: 1822
- Joined: Thu Mar 09, 2006 11:54 pm
- Location: The Netherlands
Re: Hash table division
Actually Bob you were doing 2 total different lookup until start of this century. Even some years after i noticed it and wrote about it several times in the forum, Crafty kept losing system time to 2 random probes.bob wrote:I simply xor a STM value. I'm not sure I'd want two different tables. What happens in positions where one side has lots of mobility and one side is very restricted? One table fills up, the other is barely used...sje wrote:Symbolic has always done this with one table for WTM and one for BTM.
I've never thought, in any scenario, that two separate tables works, unless you talk about two tables in the Belle sense, where one is a depth-preferred replacement strategy while the other is an always-store table. But for Belle, both store both WTM/BTM entries, so there is no "side-to-move boundary".
Now i say this in my own words: when it was convenient to wintel programmer Eugene Nalimov, to change that, he did do so.
Of course not for his employer, it was done well in time before AMD had a faster latency to the RAM with opteron and built in memory controller in k8, so we can't prove any relationship there. Sincethen you're also doing sequential probes Bob
And not a day before until Eugene modified that...
Vincent
p.s. normally spoken specint2004 would have released in 2004 and crafty also was a candidate for specint2004. Intel didn't have an on die memory controller until years later, so that Nalimov changed that, despite me writing it for years into the forum, was a most lucky change for wintel, which the years before that, despite mewriting it regurary in the CCC, wasn't convenient for them as during the on die memory controllers, intel had the fastest random latency. That changed to AMD's advantage when april 2003 they released the opteron that had an on die memory controller.
Interesting to see how $100 billion companies still are dependant there upon lucky coincidences... ...delaying this change that long really was lucky for them....
-
Rebel

- Posts: 7546
- Joined: Thu Aug 18, 2011 12:04 pm
- Full name: Ed Schröder
Re: Hash table division
I have a display, it gives the percentages how both HT tables fill and the odd-ply HT fills a lot faster than the even ply HT. It's exactly what one might expect from a well ordered search. And so it makes sense to declare a bigger odd-ply-HT than an even-ply-HT. Just try yourself.bob wrote:You realize that if you do an even-ply search, 1/2 of the hash stores are going to be from that last layer of even-ply searches??? That is, for every depth N-1 node where N-1 is odd, you will always see a depth N search (and probe).Rebel wrote:When implementing hash tables in the days that memory was limited (1 Mb if you were rich) I set-up my hash table data structure as follows:
- One hash table for odd plies
- One hash table for even plies
And where ever possible make the odd ply HT twice as big as the even ply HT because that one is accessed the most due to the AB behaviour. And it also worked great in case of a full HT. Anno 2012 I wonder if that's still the case.
Anyone using a somewhat similar system ?
I don't see why this makes any sense at all...
-
diep
- Posts: 1822
- Joined: Thu Mar 09, 2006 11:54 pm
- Location: The Netherlands
Re: Hash table division
Maybe Bob didn't understand you mean odd iterations versus even iterations.Rebel wrote:I have a display, it gives the percentages how both HT tables fill and the odd-ply HT fills a lot faster than the even ply HT. It's exactly what one might expect from a well ordered search. And so it makes sense to declare a bigger odd-ply-HT than an even-ply-HT. Just try yourself.bob wrote:You realize that if you do an even-ply search, 1/2 of the hash stores are going to be from that last layer of even-ply searches??? That is, for every depth N-1 node where N-1 is odd, you will always see a depth N search (and probe).Rebel wrote:When implementing hash tables in the days that memory was limited (1 Mb if you were rich) I set-up my hash table data structure as follows:
- One hash table for odd plies
- One hash table for even plies
And where ever possible make the odd ply HT twice as big as the even ply HT because that one is accessed the most due to the AB behaviour. And it also worked great in case of a full HT. Anno 2012 I wonder if that's still the case.
Anyone using a somewhat similar system ?
I don't see why this makes any sense at all...