Not sure anymore what you call a 'layer' here. Does that include the 512 cells initialized as the old network? We are dealing with 2 new layers of weights here, even if there only is one layer of new cells. It doesn't help you that the complete layers are nonzero. Because a nonzero gradient doesn't help you if it has a zero component along an isolated part of the network.
If you don't believe it, try it.
How to make a double-sized net as good as SF NNUE in a few easy steps
Moderators: hgm, Rebel, chrisw
-
hgm

- Posts: 27869
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
-
connor_mcmonigle
- Posts: 543
- Joined: Sun Sep 06, 2020 4:40 am
- Full name: Connor McMonigle
Re: How to make a double-sized net as good as SF NNUE in a few easy steps
Just zero initializing the new weights would work perfectly fine. It might be inferior to just initializing with some normal noise, though. Of course, then you break the behavior that outputs exactly match, but I don't think this is a big deal in practice.chrisw wrote: ↑Mon Mar 01, 2021 12:05 amOne could, instead of zero-ing the right hand side, initialise it with what would have gone into the left hand side (the weights from the factoriser). Then RHS weights to hidden layer are set duplicate the already existing from LHS. Would that work?connor_mcmonigle wrote: ↑Sun Feb 28, 2021 11:52 pmNo worries. The output of a given layer isn't immediately relevant to calculating the gradient w.r.t its weight matrix (we need the gradient w.r.t to the output, not the output itself). The layer's input will also be nonzero as the layer is given the board (halfKP) features as input. As both the gradient w.r.t the first layer's output and the input vector are both nonzero, the gradient w.r.t to the first layer weight matrix is also nonzero.
-
connor_mcmonigle
- Posts: 543
- Joined: Sun Sep 06, 2020 4:40 am
- Full name: Connor McMonigle
Re: How to make a double-sized net as good as SF NNUE in a few easy steps
I don't actually know quite what you mean by cells. Do you mean matrix entries? If so, there are far more than 512 that get added with chrisw's scheme...hgm wrote: ↑Mon Mar 01, 2021 12:08 am Not sure anymore what you call a 'layer' here. Does that include the 512 cells initialized as the old network? We are dealing with 2 new layers of weights here, even if there only is one layer of new cells. It doesn't help you that the complete layers are nonzero. Because a nonzero gradient doesn't help you if it has a zero component along an isolated part of the network.
If you don't believe it, try it.
Last edited by connor_mcmonigle on Mon Mar 01, 2021 12:11 am, edited 1 time in total.
-
hgm
- Posts: 27869
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: How to make a double-sized net as good as SF NNUE in a few easy steps
As long as they start as multiples of each other, they will never give you anything new, no matter how much training you do.
-
hgm
- Posts: 27869
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: How to make a double-sized net as good as SF NNUE in a few easy steps
Neural networks consist of cells and connections. The connections have weights associated with them, the cells apply the transfer function (which seems to be Relu here) to their total input.connor_mcmonigle wrote: ↑Mon Mar 01, 2021 12:11 amI don't actually know quite what you mean by cells. Do you mean matrix entries? If so, there are far more than 512...
In the proposed case there are 512 new cells. Each cell has 32 output connections to the 32 already existing cells of the next layer (so 32x512 new weights). They have each 64x64x5x2 input connections (so 512x40960 new weights).
-
connor_mcmonigle
- Posts: 543
- Joined: Sun Sep 06, 2020 4:40 am
- Full name: Connor McMonigle
Re: How to make a double-sized net as good as SF NNUE in a few easy steps
I'm not really familiar with that terminology. It's much easier to think about this in terms of matrix multiplication for me.hgm wrote: ↑Mon Mar 01, 2021 12:13 amNeural networks consist of cells and connections. The connections have weights associated with them, the cells apply the transfer function (which seems to be Relu here) to their total input.connor_mcmonigle wrote: ↑Mon Mar 01, 2021 12:11 amI don't actually know quite what you mean by cells. Do you mean matrix entries? If so, there are far more than 512...
In any case, I now see I was kind of derping out
For some reason I thought only part of one layer (the first layer) would be getting zero initialized.
With chrisw's scheme, two layers would have to be altered (first and second). If one were to zero initialize all the new weights, then we would have the problem you describe. However, if you use the original initialization (nonzero) scheme on the second layer's new weights and just zero initialize the added weights in the first layer, all should work. Namely, we maintain the property that the output of the new network will exactly match and don't have a zero gradient.
-
mar
- Posts: 2568
- Joined: Fri Nov 26, 2010 2:00 pm
- Location: Czech Republic
- Full name: Martin Sedlak
Re: How to make a double-sized net as good as SF NNUE in a few easy steps
this is how I imagine Chris's idea, I hope I got the numbers right:
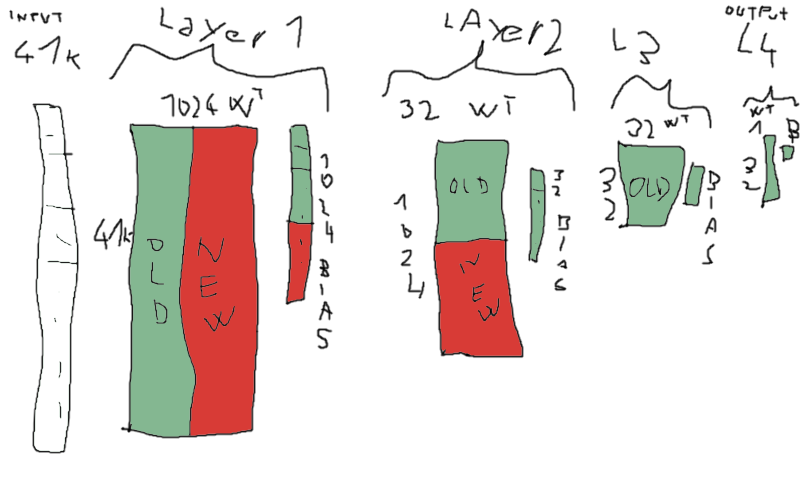
indeed, it can be viewed simply as matrix-vector multiplication which is nothing but a series of dot products
I like to imagine transposed weight matrix, biases could be encoded as part of the weight matrix with implied corresponding input set to 1
(red parts are new weights)
so basically you create a temp buffer and initialize with biases, then multiply the weights with corresponding input and sum (=fma). if spills can be avoided, it's actually quite easy for modern compilers to vectorize this, but that's not the point
I've tried it on a much smaller net (MNIST - unrelated to chess) and it works, however I use a stochastic approach, not backpropagation.
and it works, but I have the feeling that the trainer has a hard time to actually improve, despite the fact that the 1st hidden layer contains
twice the amount of weights. probably more "epochs" is needed.
the larger net is 784-256-64-10 but it seems I'm already beating (test set accuracy 97.16% = 2.84% error) the results of a 784-500-150-10 net mentioned here: http://yann.lecun.com/exdb/mnist/, my best 784-128-64-10 had 96.88% test set accuracy already.
note that I use leaky ReLU (x<0 => epsilon*x else x), haven't compared to max(x, 0) yet so no idea if it's actually beneficial at all
the problem is that this 2x bigger net will have 2x slower inference, so it has to pay for itself in terms of performance.
not sure if Chris's approach is viable, but might be worth trying. In fact, why double and not try something like 3/2, but I'm sure SF devs tried
many other topologies and they know what worked best for them.
indeed, it can be viewed simply as matrix-vector multiplication which is nothing but a series of dot products
I like to imagine transposed weight matrix, biases could be encoded as part of the weight matrix with implied corresponding input set to 1
(red parts are new weights)
so basically you create a temp buffer and initialize with biases, then multiply the weights with corresponding input and sum (=fma). if spills can be avoided, it's actually quite easy for modern compilers to vectorize this, but that's not the point
I've tried it on a much smaller net (MNIST - unrelated to chess) and it works, however I use a stochastic approach, not backpropagation.
and it works, but I have the feeling that the trainer has a hard time to actually improve, despite the fact that the 1st hidden layer contains
twice the amount of weights. probably more "epochs" is needed.
the larger net is 784-256-64-10 but it seems I'm already beating (test set accuracy 97.16% = 2.84% error) the results of a 784-500-150-10 net mentioned here: http://yann.lecun.com/exdb/mnist/, my best 784-128-64-10 had 96.88% test set accuracy already.
note that I use leaky ReLU (x<0 => epsilon*x else x), haven't compared to max(x, 0) yet so no idea if it's actually beneficial at all
the problem is that this 2x bigger net will have 2x slower inference, so it has to pay for itself in terms of performance.
not sure if Chris's approach is viable, but might be worth trying. In fact, why double and not try something like 3/2, but I'm sure SF devs tried
many other topologies and they know what worked best for them.
-
hgm
- Posts: 27869
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: How to make a double-sized net as good as SF NNUE in a few easy steps
Yes, but there are actual two fatal problems, and this solves only one of them:connor_mcmonigle wrote: ↑Mon Mar 01, 2021 12:20 amWith chrisw's scheme, two layers would have to be altered (first and second). If one were to zero initialize all the new weights, then we would have the problem you describe. However, if you use the original initialization (nonzero) scheme on the second layer's new weights and just zero initialize the added weights in the first layer, all should work. Namely, we maintain the property that the output of the new network will exactly match and don't have a zero gradient.
1) Cells that have both (only) zero input- and zero output-weights will remain dead forever. This can be solved by copying the weights of the old network in the second layer of weights.
2) Changes of corresponding input-weights to cells that have the same (or proportional) output weights will contribute the same to the gradient. As a consequence these will for ever change in lockstep. They are not really independent new cells at all; they mimic the contribution of the existing cell from which you copied the output-weights.
So this is just an outrageously expensive method of replacing the ReLu transfer function min(c, input) by min(c1, input) + min(c2, c3*input), where you don't make use of the fact that 'input' is the same in both terms, but recalculate it from scratch. It is not really a bigger net at all. Just a net with a slightly modified transfer function in the first hidden layer, that takes as much time to update as a bigger net.
-
connor_mcmonigle
- Posts: 543
- Joined: Sun Sep 06, 2020 4:40 am
- Full name: Connor McMonigle
Re: How to make a double-sized net as good as SF NNUE in a few easy steps
I was not suggesting any old weights be copied into newly added (red) weights.hgm wrote: ↑Mon Mar 01, 2021 9:12 am
2) Changes of corresponding input-weights to cells that have the same (or proportional) output weights will contribute the same to the gradient. As a consequence these will for ever change in lockstep. They are not really independent new cells at all; they mimic the contribution of the existing cell from which you copied the output-weights.
By "original weight initialization scheme", I meant randomly initialize (with samples from some centered uniform distribution) the new weights introduced to the second layer.
My proposed solution was to randomly initialize layer 2's red blob in Martin's diagram. All the remaining new weights are zero initialized. This would preserve the original output while insuring the gradients are nonzero and don't "update weights in lock step", in my understanding.
-
hgm
- Posts: 27869
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller