@Fulvio
I think it would be very helpful to document the .si4 file format. Note that there is already (russian) website which documents some parts of the format: http://kvetka.org/SG4_format.shtml
It is missing some things however, for example the "Homepawn" datastructure. As far as I understand, it records the order on how pawns moved from their initial position in order to quickly sort out non-fitting opening positions.
If you plan a successor format, my recommendation would be to vastly simplify the whole thing. For example using two bytes to encode a move of course doubles the required space, but makes parsing much simple. With larger hard drives space is no longer such a big concern compared to twenty years ago. This would help interoparability. .si4 is essentially one supported by scid forks and derivates, no one else has (dared) to implement that.
SCID4 database
Moderator: Ras
-
Sopel
- Posts: 400
- Joined: Tue Oct 08, 2019 11:39 pm
- Full name: Tomasz Sobczyk
Re: SCID4 database
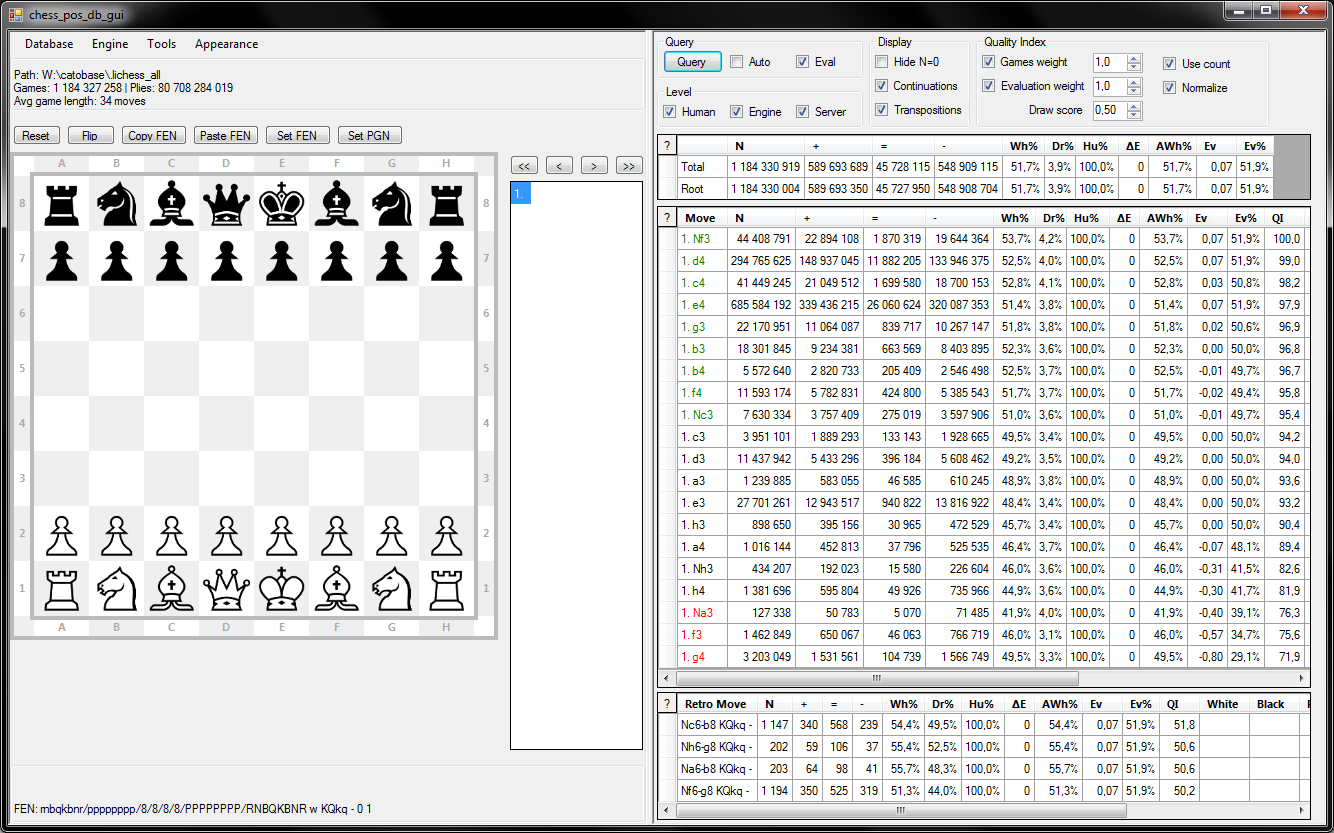
https://github.com/Sopel97/chess_pos_db, https://github.com/Sopel97/chess_pos_db_gui
This project aims to solve a slightly different problem than SCID, but some things might still be applicable. chess_pos_db is mostly made for fast WDL queries with at most one game (last/first) link. It's battle tested with >1B games (lichess), ~80B plies, and ~1TB total size, ~15h total build time on a single HDD (https://raw.githubusercontent.com/Sopel ... g/main.png). Notable things that might be helpful to consider for SCID, mostly concerning a position storage:
- each unique position is stored individually
- positions are identified by a 72-80-bit zobrist hash, which means collisions are very rare. If a bijective map is needed then one can use 24B compressed position https://github.com/Sopel97/chess_pos_db ... 1125-L1158
- position entries have fixed length
- entries in a single file are ordered by hash, more than one file supported, files are append-only
- additionally there's a blocked index for each file, designed to be stored fully in memory, with one entry for ~1000 positions. Means that queries are O(1) and require minimal IO (read ~64k chunk and do search in memory). Additionally one could consider compressing such blocks with zstd + something like blosc (bit-wise transpose), my experiments show that this could reduce the size by ~20-30%, depending on what is stored; bit-wise transpose of the entries is important since the entries are ordered by the key.
- multiple files can be merged (k-way external merge, needs some additional logic to combine identical entries). Less files = better performance
- separate entries for W D L. Each entry encodes one bit of the count. One bit signifies whether there's a next entry with the next bit. Basically variable length encoding with 1 bit blocks. Works well for the common distributions, >95% of positions are unique usually. What I call "Smeared" entry. https://github.com/Sopel97/chess_pos_db ... #L215-L747
- additionally a "reverse move" is stored to know in which way the position arrived. Very cool and allows going through the games backwards (I don't know any other DB that can do it) https://github.com/Sopel97/chess_pos_db ... h#L27-L211
- support for multiple linked games might be problematic, depending on how many you want, as you'd need each entry to have all game ids (and juggle them when merging/adding positions). Alternatively, since we have log(n) entries, where n is the W/D/L count, one could store one game link per entry to have a variable number of games.
- filtering support can be added by splitting entries by some trait you'd like to filter by (so that one can filter for transpositions). This increases number of entries exponentially so needs to be chosen well. For example bucket entries by month, or 100 elo chunks. This is a point where more than schema would be useful, to let the user choose what they want, otherwise it gets bad quickly.
- a way to act like a server, so that other programs can make queries, for examply by json through tcp
- storing the moves for positional queries could utilize some variation of https://www.chessprogramming.org/Encodi ... and_Square, https://github.com/Sopel97/chess_pos_db ... _length.md. Basically a modified version of the old 1-byte encoding index into movelist, where you only consider either pseudo-legal move, or some other encoding that doesn't require generating the moves (see the cpwiki link). In my experience it's faster than a corner-cutting PGN parser. You can get it to ~6 bits per move with good parsing speeds.
This project aims to solve a slightly different problem than SCID, but some things might still be applicable. chess_pos_db is mostly made for fast WDL queries with at most one game (last/first) link. It's battle tested with >1B games (lichess), ~80B plies, and ~1TB total size, ~15h total build time on a single HDD (https://raw.githubusercontent.com/Sopel ... g/main.png). Notable things that might be helpful to consider for SCID, mostly concerning a position storage:
{kind=link}
- each unique position is stored individually
- positions are identified by a 72-80-bit zobrist hash, which means collisions are very rare. If a bijective map is needed then one can use 24B compressed position https://github.com/Sopel97/chess_pos_db ... 1125-L1158
- position entries have fixed length
- entries in a single file are ordered by hash, more than one file supported, files are append-only
- additionally there's a blocked index for each file, designed to be stored fully in memory, with one entry for ~1000 positions. Means that queries are O(1) and require minimal IO (read ~64k chunk and do search in memory). Additionally one could consider compressing such blocks with zstd + something like blosc (bit-wise transpose), my experiments show that this could reduce the size by ~20-30%, depending on what is stored; bit-wise transpose of the entries is important since the entries are ordered by the key.
- multiple files can be merged (k-way external merge, needs some additional logic to combine identical entries). Less files = better performance
- separate entries for W D L. Each entry encodes one bit of the count. One bit signifies whether there's a next entry with the next bit. Basically variable length encoding with 1 bit blocks. Works well for the common distributions, >95% of positions are unique usually. What I call "Smeared" entry. https://github.com/Sopel97/chess_pos_db ... #L215-L747
- additionally a "reverse move" is stored to know in which way the position arrived. Very cool and allows going through the games backwards (I don't know any other DB that can do it) https://github.com/Sopel97/chess_pos_db ... h#L27-L211
- support for multiple linked games might be problematic, depending on how many you want, as you'd need each entry to have all game ids (and juggle them when merging/adding positions). Alternatively, since we have log(n) entries, where n is the W/D/L count, one could store one game link per entry to have a variable number of games.
- filtering support can be added by splitting entries by some trait you'd like to filter by (so that one can filter for transpositions). This increases number of entries exponentially so needs to be chosen well. For example bucket entries by month, or 100 elo chunks. This is a point where more than schema would be useful, to let the user choose what they want, otherwise it gets bad quickly.
- a way to act like a server, so that other programs can make queries, for examply by json through tcp
- storing the moves for positional queries could utilize some variation of https://www.chessprogramming.org/Encodi ... and_Square, https://github.com/Sopel97/chess_pos_db ... _length.md. Basically a modified version of the old 1-byte encoding index into movelist, where you only consider either pseudo-legal move, or some other encoding that doesn't require generating the moves (see the cpwiki link). In my experience it's faster than a corner-cutting PGN parser. You can get it to ~6 bits per move with good parsing speeds.
dangi12012 wrote:No one wants to touch anything you have posted. That proves you now have negative reputations since everyone knows already you are a forum troll.
Maybe you copied your stockfish commits from someone else too?
I will look into that.
-
Daniel Shawul
- Posts: 4186
- Joined: Tue Mar 14, 2006 11:34 am
- Location: Ethiopia
Re: SCID4 database
It makes sense to me. There must be a good reason to reinvent the wheal when there is a well tested high performance industry standard format.dangi12012 wrote: ↑Wed Oct 13, 2021 8:23 pmExcatly OP wants good performance. You store the zobrist hash as Integer primary key - and a zobrist with a different seed to eliminate any and all collisions. This gives you O(1)R. Tomasi wrote: ↑Wed Oct 13, 2021 7:21 pmYou suggest encoding positions as integers?dangi12012 wrote: ↑Wed Oct 13, 2021 7:05 pmYou are wrong also. Test it please if you dont believe it...R. Tomasi wrote: ↑Wed Oct 13, 2021 4:41 pmhttps://medium.com/@JasonWyatt/squeezin ... e175f3c346dangi12012 wrote: ↑Wed Oct 13, 2021 4:30 pm100% Wrong.Rein Halbersma wrote: ↑Wed Oct 13, 2021 2:04 pmLookup on indices is O(log N), not O(1).dangi12012 wrote: ↑Mon Oct 11, 2021 10:38 pm As I told you - with SQL you get O(1) lookup performance on primary keys. You dont have to take it from me - literally anyone working in IT industry with some SQL experience can verify.
https://www.geeksforgeeks.org/sql-query-complexity/
O(log(N)) is for a binary search. Which you would have to do for a primary STRING key.
But not nor a primary INTEGER key. Which is a hashtable lookup like a C++ map. Its O(1).
Thank's for the link, though. Didn't know integral keys were O(1)!
I know it works because I used it in my last years project to have a lookup for any and all positions from 2013 - 2020 that have ever been played on lichess. Including SF rating - outcome and all usernames.
Everything at once doesnt fit but up to 120GB or so sqlite is blazingly fast to lookup any position + how often it was reached..
I made my point clear that reinventing a custom DB will be a painful slow process and at the end of the day data integrity and features like deduplication and compression are much much harder to implement not to mention the advanced B tree implentation you need when looking stuff up.
What you will end up will be slower - error prone and no developer on the world can maintain it for you.
Maybe I will release my parser - since it transforms any of these .pgn.bz2 into batched highly compatible sql insert statements.
https://database.lichess.org/
-
Daniel Shawul
- Posts: 4186
- Joined: Tue Mar 14, 2006 11:34 am
- Location: Ethiopia
Re: SCID4 database
You are being stubborn, dangi12012 clearly makes good points and it seems he has code to back it up.Fulvio wrote: ↑Wed Oct 13, 2021 7:59 pmDirectly from the sqlite website:dangi12012 wrote: ↑Wed Oct 13, 2021 7:05 pm You are wrong also. Test it please if you dont believe it...
https://www.geeksforgeeks.org/sql-query-complexity/
O(log(N)) is for a binary search. Which you would have to do for a primary STRING key.
But not nor a primary INTEGER key. Which is a hashtable lookup like a C++ map. Its O(1).
Please dont invent a binary database format. It will be slower - debugging will take forever and at the end of the day you dont have a standard like sql everyone can rely on - and have experience with. Im not even starting with data integrity even during unexpected crashes... Thats what databases do for you
"One technique for avoiding a full table scan is to do lookups by rowid (or by the equivalent INTEGER PRIMARY KEY)."
"Since the information is stored in the table in rowid order, SQLite can find the correct row using a binary search. If the table contains N elements, the time required to look up the desired row is proportional to logN rather than being proportional to N as in a full table scan."
https://www.sqlite.org/queryplanner.html
Now, your posts are useless, offtopic and full of unbacked claims.
So, can you please stop trolling? (and for the others please do not feed the troll)
Didn't you already wrote: "I wont post here anymore".
So, please, stick to that.
You on the other hand, have a 20 year old format, that you believe is world's best.
What is the point of your post anyway ? To get feedback or brag about how fast your code is?
-
Fulvio
- Posts: 399
- Joined: Fri Aug 12, 2016 8:43 pm
Re: SCID4 database
Thanks!ndbd wrote: ↑Sat Oct 16, 2021 9:58 pm I think it would be very helpful to document the .si4 file format. Note that there is already (russian) website which documents some parts of the format: http://kvetka.org/SG4_format.shtml
I used gooogle translate and the description seems correct and detailed.
Summarizing, the .sg4 file (GameData) contains the remaining information for each game:
- the other tags that are not stored in the IndexEntry (https://sourceforge.net/p/scid/code/ci/ ... ebuf.h#l39)
- the optional FEN of the initial position
- the moves of the game
- the comments
The moves are encoded in one byte and the most significant 4-bits are the index of the moving piece (https://sourceforge.net/p/scid/code/ci/ ... buf.h#l301 ).
The king always has index 0 and this implies that all the moves of the other pieces always have a value >15. The possible moves of a king are only 8 and this leaves room for encoding special values:
0 -> null move
9 -> castle queenside
10 -> castle kingside
11 -> NAG
12 -> comment
13 -> start variation
14 -> end variation
15 -> end game
So, for example, "O-O {a comment}" is encoded with the two bytes 10 12 and the comment text is inserted at the end of the appropriate section.
Pay attention that the value of the NAGs are inserted together with the moves. For example "O-O =" is encoded with the three bytes 10 11 14. So to be sure that a byte represents a special value, you must also check that it is not preceded by a NAG byte with value 11.
10) The most important limitation in my opinion is that neither the tags nor the comments are compressed in any way. It is now common to have games where the clock and the eventual evaluation of each position are stored as comments, and it would be possible to save a lot of space.
-
Fulvio
- Posts: 399
- Joined: Fri Aug 12, 2016 8:43 pm
Re: SCID4 database
Yes. When looking for a position, you look at how many white pawns there are in rank 2 and how many black pawns there are in rank 7 (the "home" ranks).
https://sourceforge.net/p/scid/code/ci/ ... sig.h#l293
Then you recreate the position of the home pawns in the compared game with the same number of pawns in the starting ranks. If they are not the same, the position cannot be reached.
I thought the same years ago. However, while it's counterintuitive, the size of the games also affects the searching speed (which is why I would like to compress comments or even move them to a separate file). A format that is simpler and faster to process, but which requires double the space, would be slower.
-
Sopel
- Posts: 400
- Joined: Tue Oct 08, 2019 11:39 pm
- Full name: Tomasz Sobczyk
Re: SCID4 database
last time I tried postgres the bulk insert was about 100x slower than my db written from scratch (~10k compared to >1M /s). And that was on an almost empty db, imagine inserting when there's billions of rows (my approach on the other hand has the same speed regardless of the size). Also the db was taking significantly more space than mine approachDaniel Shawul wrote: ↑Sun Oct 17, 2021 12:53 pmYou are being stubborn, dangi12012 clearly makes good points and it seems he has code to back it up.Fulvio wrote: ↑Wed Oct 13, 2021 7:59 pmDirectly from the sqlite website:dangi12012 wrote: ↑Wed Oct 13, 2021 7:05 pm You are wrong also. Test it please if you dont believe it...
https://www.geeksforgeeks.org/sql-query-complexity/
O(log(N)) is for a binary search. Which you would have to do for a primary STRING key.
But not nor a primary INTEGER key. Which is a hashtable lookup like a C++ map. Its O(1).
Please dont invent a binary database format. It will be slower - debugging will take forever and at the end of the day you dont have a standard like sql everyone can rely on - and have experience with. Im not even starting with data integrity even during unexpected crashes... Thats what databases do for you
"One technique for avoiding a full table scan is to do lookups by rowid (or by the equivalent INTEGER PRIMARY KEY)."
"Since the information is stored in the table in rowid order, SQLite can find the correct row using a binary search. If the table contains N elements, the time required to look up the desired row is proportional to logN rather than being proportional to N as in a full table scan."
https://www.sqlite.org/queryplanner.html
Now, your posts are useless, offtopic and full of unbacked claims.
So, can you please stop trolling? (and for the others please do not feed the troll)
Didn't you already wrote: "I wont post here anymore".
So, please, stick to that.
You on the other hand, have a 20 year old format, that you believe is world's best.
What is the point of your post anyway ? To get feedback or brag about how fast your code is?
dangi12012 wrote:No one wants to touch anything you have posted. That proves you now have negative reputations since everyone knows already you are a forum troll.
Maybe you copied your stockfish commits from someone else too?
I will look into that.
-
dangi12012
- Posts: 1064
- Joined: Tue Apr 28, 2020 10:03 pm
- Full name: Daniel Infuehr
Re: SCID4 database
Or you solve that problem perfectly by using a double zobrist hash? Nothing is preventing you to have blob columns in an sql DB. So it would be best of the two worlds. I think you are not interested in different ideas and are dead set on a custom written hard to maintain binary format. As I said speed is a non issue with SQL and chess problems. It is also an industry tested standard.Fulvio wrote: ↑Sun Oct 17, 2021 1:54 pmYes. When looking for a position, you look at how many white pawns there are in rank 2 and how many black pawns there are in rank 7 (the "home" ranks).
https://sourceforge.net/p/scid/code/ci/ ... sig.h#l293
Then you recreate the position of the home pawns in the compared game with the same number of pawns in the starting ranks. If they are not the same, the position cannot be reached.
I thought the same years ago. However, while it's counterintuitive, the size of the games also affects the searching speed (which is why I would like to compress comments or even move them to a separate file). A format that is simpler and faster to process, but which requires double the space, would be slower.
Good luck!
Worlds-fastest-Bitboard-Chess-Movegenerator
Daniel Inführ - Software Developer
Daniel Inführ - Software Developer
-
Fulvio
- Posts: 399
- Joined: Fri Aug 12, 2016 8:43 pm
Re: SCID4 database
I had a quick look, if I'm not mistaken it is similar to Lichess' Opening ExplorerSopel wrote: ↑Sun Oct 17, 2021 12:14 pm https://github.com/Sopel97/chess_pos_db, https://github.com/Sopel97/chess_pos_db_gui
This project aims to solve a slightly different problem than SCID, but some things might still be applicable. chess_pos_db is mostly made for fast WDL queries with at most one game (last/first) link.
https://github.com/niklasf/lila-openingexplorer
https://lichess.org/blog/Vs0xMTAAAD4We4 ... g-explorer
which uses Kyoto Cabinet?
https://dbmx.net/kyotocabinet/
-
Sopel
- Posts: 400
- Joined: Tue Oct 08, 2019 11:39 pm
- Full name: Tomasz Sobczyk
Re: SCID4 database
kinda, except designed for much larger number of games (in the order of 100x). And with less importance on the individial games.Fulvio wrote: ↑Sun Oct 17, 2021 6:13 pmI had a quick look, if I'm not mistaken it is similar to Lichess' Opening ExplorerSopel wrote: ↑Sun Oct 17, 2021 12:14 pm https://github.com/Sopel97/chess_pos_db, https://github.com/Sopel97/chess_pos_db_gui
This project aims to solve a slightly different problem than SCID, but some things might still be applicable. chess_pos_db is mostly made for fast WDL queries with at most one game (last/first) link.
https://github.com/niklasf/lila-openingexplorer
https://lichess.org/blog/Vs0xMTAAAD4We4 ... g-explorer
which uses Kyoto Cabinet?
https://dbmx.net/kyotocabinet/
dangi12012 wrote:No one wants to touch anything you have posted. That proves you now have negative reputations since everyone knows already you are a forum troll.
Maybe you copied your stockfish commits from someone else too?
I will look into that.