Moderator: Ras

What you see as "contempt" is actually "failure to convert". As you balance the overall elo, LC0 will in general be stronger and obtain better positions, but fail to convert or blunder them and lose. The overall result is a wash (by design of the experiment).Laskos wrote: ↑Sat Jan 19, 2019 1:36 pm
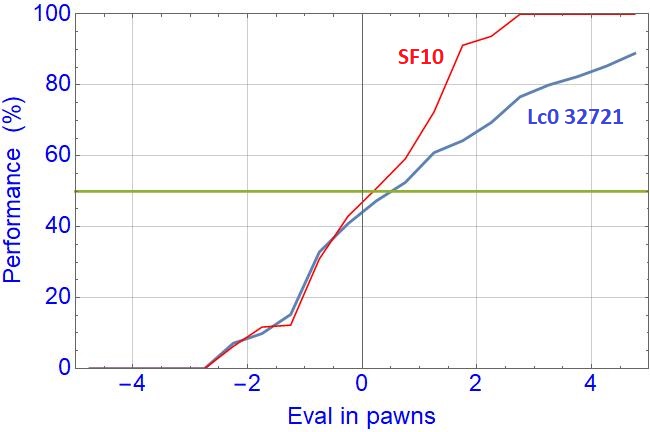
Lc0, to smaller degree, still has difficulty converting even large evals it shows. It exhibits a sort of Contempt of some 60cp. SF10 has an in-built Contempt of about 20cp. This difficulty converting of Lc0 is probably again related to bad endgames and occasional blunders.
But the negative evals of Lc0 show almost exact performance as SF10, it behaves regularly when seeing itself in disadvantage.
Well, it is still contempt of some 60cp. Say, against an equal or stronger regular engine, if Leela's eval is +40cp, it should rather forcefully draw if it can, than hoping to get a better result, as +40cp has some 48% performance, or -14 Elo points average outcome (against an equal regular engine, even worse against a superior engine).yanquis1972 wrote: ↑Sun Jan 20, 2019 11:20 am I think that’s the major factor, especially at this TC, but “comtempt” (relatively dramatic cp scores) also plays a part...when possible I exclusively use win% with leela now because after a short time you can understand her evaluation in traditional “+-, +/-, +/=“, etc terms. If the cp value is intended to mimic a/b evals it does so poorly....
What I don’t immediately understand is why leelas negative evals plot so well with stockfishes, but I’d bet that again precise conversion is the primary factor.
I think this “asymmetry” is just an effect of the way the search finds an evaluation. The explore exploit algorithm favours searching “good” moves. The search at any node doesn’t go full width. The backed up evaluation averages what has been looked at. So the score tends to be an averaging over the better lines in the tree. Hence positively asymmetric.Laskos wrote: ↑Sun Jan 20, 2019 11:41 amWell, it is still contempt of some 60cp. Say, against an equal or stronger regular engine, if Leela's eval is +40cp, it should rather forcefully draw if it can, than hoping to get a better result, as +40cp has some 48% performance, or -14 Elo points average outcome (against an equal regular engine, even worse against a superior engine).yanquis1972 wrote: ↑Sun Jan 20, 2019 11:20 am I think that’s the major factor, especially at this TC, but “comtempt” (relatively dramatic cp scores) also plays a part...when possible I exclusively use win% with leela now because after a short time you can understand her evaluation in traditional “+-, +/-, +/=“, etc terms. If the cp value is intended to mimic a/b evals it does so poorly....
What I don’t immediately understand is why leelas negative evals plot so well with stockfishes, but I’d bet that again precise conversion is the primary factor.
I am not sure why for negative evals, Leela's performance shape is so similar to that of SF10. It seems that what Leela considers as an inferior position is seen by SF10 also as inferior, of similar (negative) cp value.
Sure, for those high (positive) Leela's eval values, the main reason is failure to convert, including blunders.
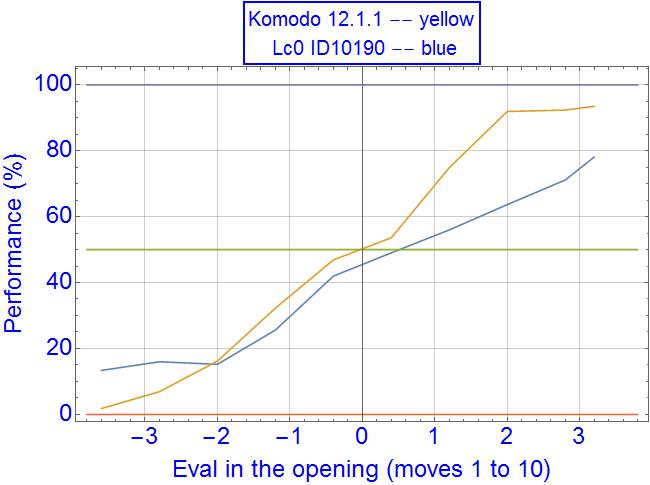
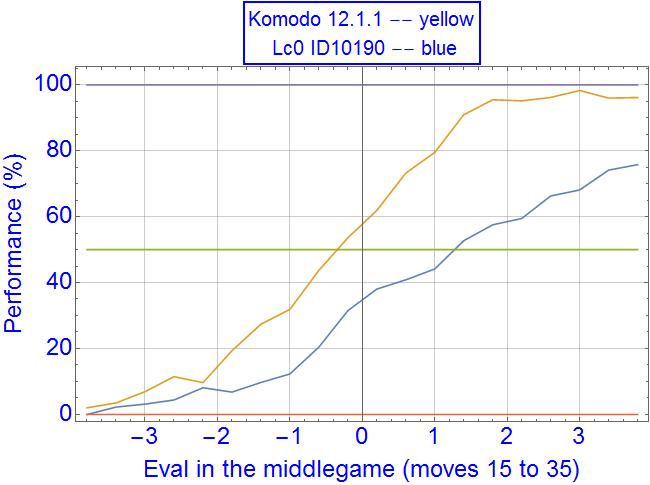
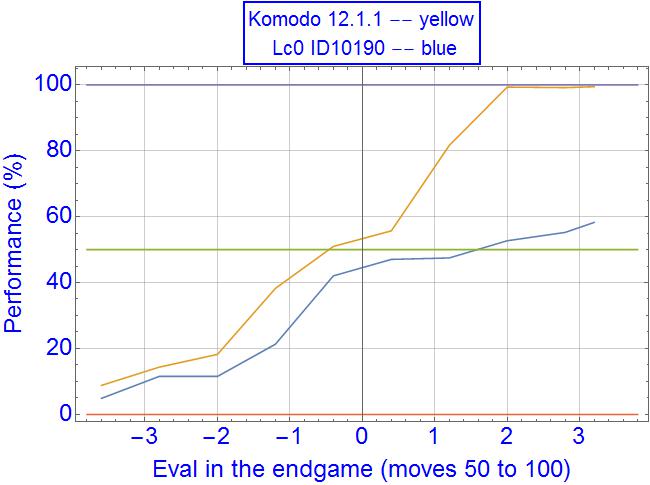
I am not using win% output with Leela, what does it say for 300cp-400cp values in early midgame? Here it is around 80-85% performance, against an equal in strength SF10. Do they use some general logistic conversion or it's more complicated and dependent on each position?