Hi Luis,
I'm afraid it gets more complicated with each new post ... I was already about to reply to your questions, then I received an "interrupt", now I'm back and see what you wrote in the meantime.
So let me first reply to your question regarding
move ordering. Afterwards I'll adress the alpha-beta topic which needs quite a different approach in your case, in my opinion.
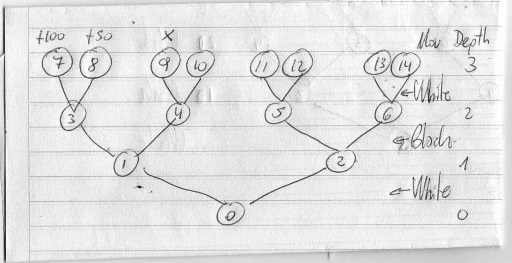
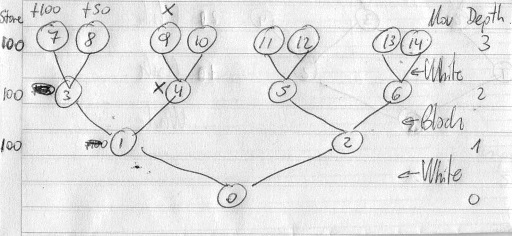
- Move ordering based on PV: You cannot store the whole tree that you have searched during some iteration N, it is simply too large. What you store is at least the best root move, or even better, the PV of the root node. You can use this to start iteration N+1 by searching that PV first: at root (ply 0), search PV[0] first, and once you are there, search PV[1] first, and so on. This will only affect the "leftmost" branches of your tree (if you look at your own "move ordering picture" you will understand what I mean). Whenever at some node you have finished searching the PV node and continue with the next move you can't use anything from that "root PV" any longer. I guess you know that already.
Apart from this move ordering based on the PV of the previous iteration, there are also other kinds of move ordering tools that are based on information saved during previous parts of the search, e.g. the transposition table, killer moves, or history heuristics. I guess you are currently using none of these.
So when talking about move ordering, everything else is about "static move ordering" based solely on characteristics of the given move and the current board. Usually we prefer captures (and promotions) over quiet moves, and among captures we prefer capturing the opponent's higher-valued pieces over the lower-valued ones, and if two moves are still equal then we prefer capturing with our least-valued aggressor. That's all about MVV/LVA ordering which we usually apply to all capture moves.
So what you should try to achieve, in your current state, is:
a) If you are on the (small) path given by the saved PV of the previous iteration then try the PV move belonging to the current node first.
b) Otherwise, try all captures prior to all other moves, obeying the MVV/LVA order for captures as described above. I would try non-capturing promotions after capturing any knights/bishops but before capturing any pawns, but this can also be done differently. (Don't assume that a promotion wins a queen, though.) The order of all other (quiet) moves does not matter much for you in the beginning. But trying captures first is crucial.
- Now the other topic:
alpha-beta. First of all: it is almost completely unrelated to the topic of "move ordering" so you should really see this in a separate context. The alpha-beta algorithm follows the idea to reduce the number of nodes needed to search a game tree to the minimum that is required to get the correct minimax score of the root node (where "minimax" could of course be replaced by "negamax"). Its success, in terms of shrinking tree size, is greater with better move ordering (so that is the only relation to move ordering). If you search the tree by always trying the worst move first, then the second-worst etc. and finally the best one, then alpha-beta will save nothing and will search the same tree as without alpha-beta. The reason is that alpha-beta aims at avoiding to search nodes for which it is already known that their score will not affect the score of the root node. But if each move is better than its predecessor then no cutoffs are possible.
And now the bad news for you. It is hardly possible for me to walk through your example in all details, nor can I review the quite complex method you are using for your search. The reason is simple: you are doing things much too complicated. The good news is: you can do better

What you are currently doing in your tree search can - according to my current knowledge about your program - be summarized as follows:
- you use minimax (most people use negamax),
- you deviate somehow from the well-known alpha-beta algorithm,
- your search is iterative (most people use a recursive search which is also much better regarding readability and less complex for beginners),
- and you do not store generated moves in a move list but immediately make each move that you just generated, which makes any kind of static move ordering much harder.
So there are a couple of things which could make your chess-programming life easier ...
A good answer to your specific question regarding alpha-beta and why two bounds are needed can be found at
https://chessprogramming.wikispaces.com/Alpha-Beta:
The situation becomes even more complicated, however, when we go to a search depth of 3 or greater, because now both players can make choices affecting the game tree. Now we have to maintain both a lower bound and an upper bound (called Alpha and Beta.) We maintain a lower bound because if a move is too bad we don't consider it. But we also have to maintain an upper bound because if a move at depth 3 or higher leads to a continuation that is too good, the other player won't allow it, because there was a better move higher up on the game tree that he could have played to avoid this situation. One player's lower bound is the other player's upper bound.
Nevertheless, I would add that the explanation why we need a lower bound is not precise enough, for my taste. At the current node the lower bound "Alpha" (in case of Minimax it is "Alpha" for White and "Beta" for Black) is simply needed as upper bound for the opponent, while the upper bound is used directly to test for a cutoff: if a subtree returns a score that is beyond our current upper bound (in case of Minimax: >= Beta for White or <= Alpha for Black!) then we cut off all remaining subtrees since we know that we will return to our parent node with a score that is not better than the opponent's lower bound, so it will have no effect. To be able to do the same thing one ply deeper you use two bounds, one is saved for the opponent's viewpoint at the deeper node and the other is used at the current node.
I hope this helps - maybe things will become clearer when you rewrite your program, and "do it the easy way" this time

In fact recursive alpha-beta with Negamax is essentially not much more than this:
Code: Select all
int AlphaBeta(Position pos, int alpha, int beta, int depth) {
if (depth == 0) return Eval(pos); // or QSearch(pos);
GenerateMoves(pos); // store moves in move list
for (all moves in move list) {
MakeMove(pos, move);
int score = -AlphaBeta(pos, -beta, -alpha, depth - 1);
UnmakeMove(pos, move);
if (score >= beta) return beta;
if (score > alpha) alpha = score;
}
return alpha;
}

{kind=link}
{kind=link}