Thanks Robert!
Yes, I was recommended to not include checks for the moment so I just included captures.
Thanks HG!
About TT: is one of the things I was want (now I have doubts) to deal with before starting a new code to be more prepared and not did fool things that will obligue me to start again a new code as seems is happens now with move ordering.
About IID: not sure if I understand. First I simply start with ply 1 depth following by ply 2 depth and so in the same way as I did before with any depth n. Later (was my last change from version 0.06 to actual version 0.07) I started each ply n depth search with the best move of ply n-1 depth search. Is this last IID?
Starting with quiescence search
Moderators: hgm, Rebel, chrisw
-
Luis Babboni

- Posts: 464
- Joined: Sat Feb 28, 2015 4:37 pm
- Location: Argentina
-
Luis Babboni
- Posts: 464
- Joined: Sat Feb 28, 2015 4:37 pm
- Location: Argentina
Re: Starting with quiescence search
Sorry, IID is not what I thought.
I decided to work in add move ordering to Soberango before add QS then.
I think I´ll could do it without need to rewrite the code!
I decided to work in add move ordering to Soberango before add QS then.
I think I´ll could do it without need to rewrite the code!
-
Luis Babboni
- Posts: 464
- Joined: Sat Feb 28, 2015 4:37 pm
- Location: Argentina
Re: Starting with quiescence search
Hi people, sorry to bother you again. 
I´m starting fighting with move ordering and I want to be sure I do not missunderstand something.
So, if you could and want, when you have time.... I will thanksfull if you take a brief look to this:
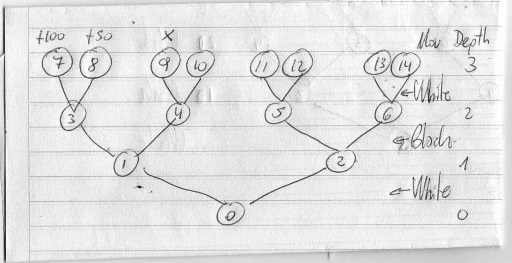
For simplicity supousse instead of around 30 possible moves from each node, we have just 2. See the image:

The images not work?
https://dl.dropboxusercontent.com/s/bxj ... c.jpg?dl=0
Actually my engine work in this way without any move ordering more than this: node 1 is the best move found in the ply 2 search did before in iterative deepening.
-Generate node 1
-Generate node 3
-Generate node 7
-Evaluate node 7 (+100)
-Generate node 3
-Generate node 8
-Evaluate node 8 (+50)
-Generate node 3
-Generate node 1
-Generate node 4
-Generate node 9
-Evaluate node 9 (x)
-Generate node 4
-if x>50 then ´(The "alphabeta" do this analisys)
..............Generate node 10.
..............Evaluate node 10.
..............Generate node 4.
Endif
-Generate node 1
-Generate node 0
-Generate node 2
etc.
So, thanks to the "alphabeta", if x <=50, I never needed to generate and evaluate node 10.
So now the questions:
-About "alpha Beta": I do not know why I need any other value than, for the moment, the 50 obteined evaluating node 8. If node 9 and node 10 evaluations are greater than 50, say 120 and 80, the new only value I will store will be the 80, but I never need two values.
-About move ordering: suppouse node 1 and node 2 you have yet ordered cause best move from previous depth iteration, the idea is to work this way?:
-Generate node 1.
-Generate node 3.
-Generate node 1.
-Generate node 4.
-Ordering node 3 and node 4
-if node 3 is before node 4 then
............Generate node 7
........... Generate node 3
........... Generate node 8
............Ordering node 7 and node 8
............ if node 7 is before node 8 then
..............................Generate node 3
..............................Generate node 7
..............................Evaluate node 7 (+100)
..............................Generate node 3
..............................Generate node 8
..............................Evaluate node 8 (+50)
Generate node 3
Generate node 1
Generate node 4
Generate node 9
Generate node 4
Generate node 10 ´That I never need to generate with my way to work!
Order node 9 and node 10
If node 9 is before node 10 then....
etc.
Showed this way, seems the second option is far more long.... but:
It is supoussed the time you first lost generating all the nodes first will be far less than the time you will gain finding that good value I talk before early?
Could be possible that in my actual point of the evaluation, I just count material, for my engine the important time consuming is in the nodes generation but in most advanced engines the time consuming is in the evaluation and for example with bitboards the nodes generation time become meanless compared to the evaluation time?
I hope I could explain myself and, of course, thanks for your time in case you take it to help me.
Best regards!
I´m starting fighting with move ordering and I want to be sure I do not missunderstand something.
So, if you could and want, when you have time.... I will thanksfull if you take a brief look to this:
For simplicity supousse instead of around 30 possible moves from each node, we have just 2. See the image:
The images not work?
https://dl.dropboxusercontent.com/s/bxj ... c.jpg?dl=0
Actually my engine work in this way without any move ordering more than this: node 1 is the best move found in the ply 2 search did before in iterative deepening.
-Generate node 1
-Generate node 3
-Generate node 7
-Evaluate node 7 (+100)
-Generate node 3
-Generate node 8
-Evaluate node 8 (+50)
-Generate node 3
-Generate node 1
-Generate node 4
-Generate node 9
-Evaluate node 9 (x)
-Generate node 4
-if x>50 then ´(The "alphabeta" do this analisys)
..............Generate node 10.
..............Evaluate node 10.
..............Generate node 4.
Endif
-Generate node 1
-Generate node 0
-Generate node 2
etc.
So, thanks to the "alphabeta", if x <=50, I never needed to generate and evaluate node 10.
So now the questions:
-About "alpha Beta": I do not know why I need any other value than, for the moment, the 50 obteined evaluating node 8. If node 9 and node 10 evaluations are greater than 50, say 120 and 80, the new only value I will store will be the 80, but I never need two values.
-About move ordering: suppouse node 1 and node 2 you have yet ordered cause best move from previous depth iteration, the idea is to work this way?:
-Generate node 1.
-Generate node 3.
-Generate node 1.
-Generate node 4.
-Ordering node 3 and node 4
-if node 3 is before node 4 then
............Generate node 7
........... Generate node 3
........... Generate node 8
............Ordering node 7 and node 8
............ if node 7 is before node 8 then
..............................Generate node 3
..............................Generate node 7
..............................Evaluate node 7 (+100)
..............................Generate node 3
..............................Generate node 8
..............................Evaluate node 8 (+50)
Generate node 3
Generate node 1
Generate node 4
Generate node 9
Generate node 4
Generate node 10 ´That I never need to generate with my way to work!
Order node 9 and node 10
If node 9 is before node 10 then....
etc.
Showed this way, seems the second option is far more long.... but:
It is supoussed the time you first lost generating all the nodes first will be far less than the time you will gain finding that good value I talk before early?
Could be possible that in my actual point of the evaluation, I just count material, for my engine the important time consuming is in the nodes generation but in most advanced engines the time consuming is in the evaluation and for example with bitboards the nodes generation time become meanless compared to the evaluation time?
I hope I could explain myself and, of course, thanks for your time in case you take it to help me.
Best regards!
-
Sven
- Posts: 4052
- Joined: Thu May 15, 2008 9:57 pm
- Location: Berlin, Germany
- Full name: Sven Schüle
Re: Starting with quiescence search
Before replying to this I have one question. Are your scores from white viewpoint (minimax) or from the moving side's viewpoint (negamax)? So far I understood that you are still using minimax. But if that is the case then the comparison of nodes 7 and 8 from your example would prefer node 7 evaluated as +100 (for White) over node 8 (only +50), since it is White to move at the parent node 3. However, you are using the +50 from node 8 as the score to compare against so something must be wrong here. With negamax it would be wrong as well (+100 > +50 from viewpoint of moving side).Luis Babboni wrote:I´m starting fighting with move ordering and I want to be sure I do not missunderstand something.
[...]
Actually my engine work in this way without any move ordering more than this: node 1 is the best move found in the ply 2 search did before in iterative deepening.
[...]
So, thanks to the "alphabeta", if x <=50, I never needed to generate and evaluate node 10.
So now the questions:
-About "alpha Beta": I do not know why I need any other value than, for the moment, the 50 obteined evaluating node 8. If node 9 and node 10 evaluations are greater than 50, say 120 and 80, the new only value I will store will be the 80, but I never need two values.
-About move ordering: suppouse node 1 and node 2 you have yet ordered cause best move from previous depth iteration, the idea is to work this way?:
Maybe I missed something in your explanation. But it is crucial to get these things right before we talk about your questions.
-
Luis Babboni
- Posts: 464
- Joined: Sat Feb 28, 2015 4:37 pm
- Location: Argentina
Re: Starting with quiescence search
Sven Schüle wrote:Before replying to this I have one question. Are your scores from white viewpoint (minimax) or from the moving side's viewpoint (negamax)? So far I understood that you are still using minimax. But if that is the case then the comparison of nodes 7 and 8 from your example would prefer node 7 evaluated as +100 (for White) over node 8 (only +50), since it is White to move at the parent node 3. However, you are using the +50 from node 8 as the score to compare against so something must be wrong here. With negamax it would be wrong as well (+100 > +50 from viewpoint of moving side).Luis Babboni wrote:I´m starting fighting with move ordering and I want to be sure I do not missunderstand something.
[...]
Actually my engine work in this way without any move ordering more than this: node 1 is the best move found in the ply 2 search did before in iterative deepening.
[...]
So, thanks to the "alphabeta", if x <=50, I never needed to generate and evaluate node 10.
So now the questions:
-About "alpha Beta": I do not know why I need any other value than, for the moment, the 50 obteined evaluating node 8. If node 9 and node 10 evaluations are greater than 50, say 120 and 80, the new only value I will store will be the 80, but I never need two values.
-About move ordering: suppouse node 1 and node 2 you have yet ordered cause best move from previous depth iteration, the idea is to work this way?:
Maybe I missed something in your explanation. But it is crucial to get these things right before we talk about your questions.
Naaaa, so sorry.... I posted it well first and delete the post and replaced by a wrong one!!!!
First question: I count points from white side.
Engine must store node 7´s value (+100)
So what I understand as the "alphabeta idea" works in a way that just generate and evaluate node 10 in case node 9 value is less than 100 cause in case is >=100, blacks do never choice node 4 cause the final score will be at least as good (for whites) as the best if its choice node 3.
I think, and hope, now I did the things right!
Here I positioned better in the draw the side to move to not confuse myself!:
https://dl.dropboxusercontent.com/s/ab6 ... c.jpg?dl=0
{kind=link}
-
Luis Babboni
- Posts: 464
- Joined: Sat Feb 28, 2015 4:37 pm
- Location: Argentina
Re: Starting with quiescence search
Mmmmm, I think I become to understadn why two values!!!
The 100 (alpha) is the value for the jump from depth 2 to depth 3.... Beta is the value for the jump between depth 1 to depth 2?
In fact now I see I do not store one value, neither 2.... I store one value for each jump between depths!!!
I´m called to lunch.... I´ll be more clear later!
The 100 (alpha) is the value for the jump from depth 2 to depth 3.... Beta is the value for the jump between depth 1 to depth 2?
In fact now I see I do not store one value, neither 2.... I store one value for each jump between depths!!!
I´m called to lunch.... I´ll be more clear later!
-
AlvaroBegue
- Posts: 931
- Joined: Tue Mar 09, 2010 3:46 pm
- Location: New York
- Full name: Álvaro Begué (RuyDos)
Re: Starting with quiescence search
The way I think about it, the recursive call in an alphabeta search is saying: "Give me the minimax score of this node if it is between alpha and beta; if it's alpha or less, I don't care exactly what it is, because the active player (the one whose turn it is on the given position) will avoid this branch and the score at the root will be unaffected; similarly if it's beta or more, the inactive player will avoid this branch and the score at the root will be unaffected."Luis Babboni wrote:Mmmmm, I think I become to understadn why two values!!!
The 100 (alpha) is the value for the jump from depth 2 to depth 3.... Beta is the value for the jump between depth 1 to depth 2?
In fact now I see I do not store one value, neither 2.... I store one value for each jump between depths!!!
I´m called to lunch.... I´ll be more clear later!
Does that make things any more clear?
-
Luis Babboni
- Posts: 464
- Joined: Sat Feb 28, 2015 4:37 pm
- Location: Argentina
Re: Starting with quiescence search
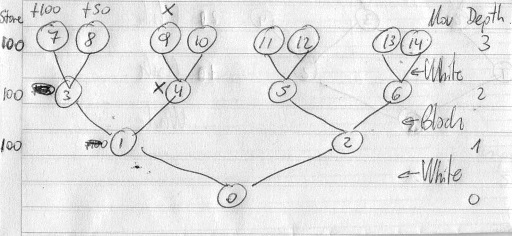
I added a new column on the left to my draw:
https://dl.dropboxusercontent.com/s/8yk ... 2.jpg?dl=0
(Sorry to ask again, there is no way to insert images? The Img button seems to not work for me.)
I´ll try to explain how my engine works:
-set flag AB to 1
-if AB=1 then generate node/position 1 (move)
-if AB=1 then generate node 3 (move)
-if AB=1 then generate node 7 (move)
-evaluate node 7 (+100)
-store value 100 at level 3.
-generate node 3 (unmove)
-if store at level 2 is empty, copy stored value at level 3 to level 2.
-if AB=1 then generate node 8 (move)
-evaluate node 8 (+50)
-generate node 3 (unmove)
-Cause level 2 store si not empty and is white turn and 50<=stored value at this level (100), do not change the value stored at level 2.
-generate node 1 (unmove)
-Cause store level at level 1 is empty, copy stored value in level 2 to level 1 store.
-if AB=1 then generate node 4 (move)
-if AB=1 then generate node 9 (move)
-evaluate node 9 (X)
-store value X at level 3
-generate node 4 (unmove)
-if stored value at level 3 (X) is > stored value at level 2 (100) then set flag AB to 0 cause black will never choice node 4 instead of node 3 cause in next move whites could choice node 9.
-Cause AB=0, instead of move from node 4 to node 10, the engine unmove to node 1. And never need to even generate node 10.
-Generate node 0. (unmove)
-Cause store at level 0 is empty, copy stored value at level 1 to level 0.
-set AB to 1.
-generate node 2. (move)
...
Each time a new value is stored in level 0, the best line is actualized with the line from actual position to the position with this new value.
The bold line is my "alpha beta" without beta!
https://dl.dropboxusercontent.com/s/8yk ... 2.jpg?dl=0
{kind=link}
(Sorry to ask again, there is no way to insert images? The Img button seems to not work for me.)
I´ll try to explain how my engine works:
-set flag AB to 1
-if AB=1 then generate node/position 1 (move)
-if AB=1 then generate node 3 (move)
-if AB=1 then generate node 7 (move)
-evaluate node 7 (+100)
-store value 100 at level 3.
-generate node 3 (unmove)
-if store at level 2 is empty, copy stored value at level 3 to level 2.
-if AB=1 then generate node 8 (move)
-evaluate node 8 (+50)
-generate node 3 (unmove)
-Cause level 2 store si not empty and is white turn and 50<=stored value at this level (100), do not change the value stored at level 2.
-generate node 1 (unmove)
-Cause store level at level 1 is empty, copy stored value in level 2 to level 1 store.
-if AB=1 then generate node 4 (move)
-if AB=1 then generate node 9 (move)
-evaluate node 9 (X)
-store value X at level 3
-generate node 4 (unmove)
-if stored value at level 3 (X) is > stored value at level 2 (100) then set flag AB to 0 cause black will never choice node 4 instead of node 3 cause in next move whites could choice node 9.
-Cause AB=0, instead of move from node 4 to node 10, the engine unmove to node 1. And never need to even generate node 10.
-Generate node 0. (unmove)
-Cause store at level 0 is empty, copy stored value at level 1 to level 0.
-set AB to 1.
-generate node 2. (move)
...
Each time a new value is stored in level 0, the best line is actualized with the line from actual position to the position with this new value.
The bold line is my "alpha beta" without beta!
-
Sven
- Posts: 4052
- Joined: Thu May 15, 2008 9:57 pm
- Location: Berlin, Germany
- Full name: Sven Schüle
Re: Starting with quiescence search
Hi Luis,
I'm afraid it gets more complicated with each new post ... I was already about to reply to your questions, then I received an "interrupt", now I'm back and see what you wrote in the meantime.
So let me first reply to your question regarding move ordering. Afterwards I'll adress the alpha-beta topic which needs quite a different approach in your case, in my opinion.
- Move ordering based on PV: You cannot store the whole tree that you have searched during some iteration N, it is simply too large. What you store is at least the best root move, or even better, the PV of the root node. You can use this to start iteration N+1 by searching that PV first: at root (ply 0), search PV[0] first, and once you are there, search PV[1] first, and so on. This will only affect the "leftmost" branches of your tree (if you look at your own "move ordering picture" you will understand what I mean). Whenever at some node you have finished searching the PV node and continue with the next move you can't use anything from that "root PV" any longer. I guess you know that already.
Apart from this move ordering based on the PV of the previous iteration, there are also other kinds of move ordering tools that are based on information saved during previous parts of the search, e.g. the transposition table, killer moves, or history heuristics. I guess you are currently using none of these.
So when talking about move ordering, everything else is about "static move ordering" based solely on characteristics of the given move and the current board. Usually we prefer captures (and promotions) over quiet moves, and among captures we prefer capturing the opponent's higher-valued pieces over the lower-valued ones, and if two moves are still equal then we prefer capturing with our least-valued aggressor. That's all about MVV/LVA ordering which we usually apply to all capture moves.
So what you should try to achieve, in your current state, is:
a) If you are on the (small) path given by the saved PV of the previous iteration then try the PV move belonging to the current node first.
b) Otherwise, try all captures prior to all other moves, obeying the MVV/LVA order for captures as described above. I would try non-capturing promotions after capturing any knights/bishops but before capturing any pawns, but this can also be done differently. (Don't assume that a promotion wins a queen, though.) The order of all other (quiet) moves does not matter much for you in the beginning. But trying captures first is crucial.
- Now the other topic: alpha-beta. First of all: it is almost completely unrelated to the topic of "move ordering" so you should really see this in a separate context. The alpha-beta algorithm follows the idea to reduce the number of nodes needed to search a game tree to the minimum that is required to get the correct minimax score of the root node (where "minimax" could of course be replaced by "negamax"). Its success, in terms of shrinking tree size, is greater with better move ordering (so that is the only relation to move ordering). If you search the tree by always trying the worst move first, then the second-worst etc. and finally the best one, then alpha-beta will save nothing and will search the same tree as without alpha-beta. The reason is that alpha-beta aims at avoiding to search nodes for which it is already known that their score will not affect the score of the root node. But if each move is better than its predecessor then no cutoffs are possible.
And now the bad news for you. It is hardly possible for me to walk through your example in all details, nor can I review the quite complex method you are using for your search. The reason is simple: you are doing things much too complicated. The good news is: you can do better What you are currently doing in your tree search can - according to my current knowledge about your program - be summarized as follows:
- you use minimax (most people use negamax),
- you deviate somehow from the well-known alpha-beta algorithm,
- your search is iterative (most people use a recursive search which is also much better regarding readability and less complex for beginners),
- and you do not store generated moves in a move list but immediately make each move that you just generated, which makes any kind of static move ordering much harder.
So there are a couple of things which could make your chess-programming life easier ...
A good answer to your specific question regarding alpha-beta and why two bounds are needed can be found at https://chessprogramming.wikispaces.com/Alpha-Beta:
I hope this helps - maybe things will become clearer when you rewrite your program, and "do it the easy way" this time In fact recursive alpha-beta with Negamax is essentially not much more than this:
In fact recursive alpha-beta with Negamax is essentially not much more than this:
I'm afraid it gets more complicated with each new post ... I was already about to reply to your questions, then I received an "interrupt", now I'm back and see what you wrote in the meantime.
So let me first reply to your question regarding move ordering. Afterwards I'll adress the alpha-beta topic which needs quite a different approach in your case, in my opinion.
- Move ordering based on PV: You cannot store the whole tree that you have searched during some iteration N, it is simply too large. What you store is at least the best root move, or even better, the PV of the root node. You can use this to start iteration N+1 by searching that PV first: at root (ply 0), search PV[0] first, and once you are there, search PV[1] first, and so on. This will only affect the "leftmost" branches of your tree (if you look at your own "move ordering picture" you will understand what I mean). Whenever at some node you have finished searching the PV node and continue with the next move you can't use anything from that "root PV" any longer. I guess you know that already.
Apart from this move ordering based on the PV of the previous iteration, there are also other kinds of move ordering tools that are based on information saved during previous parts of the search, e.g. the transposition table, killer moves, or history heuristics. I guess you are currently using none of these.
So when talking about move ordering, everything else is about "static move ordering" based solely on characteristics of the given move and the current board. Usually we prefer captures (and promotions) over quiet moves, and among captures we prefer capturing the opponent's higher-valued pieces over the lower-valued ones, and if two moves are still equal then we prefer capturing with our least-valued aggressor. That's all about MVV/LVA ordering which we usually apply to all capture moves.
So what you should try to achieve, in your current state, is:
a) If you are on the (small) path given by the saved PV of the previous iteration then try the PV move belonging to the current node first.
b) Otherwise, try all captures prior to all other moves, obeying the MVV/LVA order for captures as described above. I would try non-capturing promotions after capturing any knights/bishops but before capturing any pawns, but this can also be done differently. (Don't assume that a promotion wins a queen, though.) The order of all other (quiet) moves does not matter much for you in the beginning. But trying captures first is crucial.
- Now the other topic: alpha-beta. First of all: it is almost completely unrelated to the topic of "move ordering" so you should really see this in a separate context. The alpha-beta algorithm follows the idea to reduce the number of nodes needed to search a game tree to the minimum that is required to get the correct minimax score of the root node (where "minimax" could of course be replaced by "negamax"). Its success, in terms of shrinking tree size, is greater with better move ordering (so that is the only relation to move ordering). If you search the tree by always trying the worst move first, then the second-worst etc. and finally the best one, then alpha-beta will save nothing and will search the same tree as without alpha-beta. The reason is that alpha-beta aims at avoiding to search nodes for which it is already known that their score will not affect the score of the root node. But if each move is better than its predecessor then no cutoffs are possible.
And now the bad news for you. It is hardly possible for me to walk through your example in all details, nor can I review the quite complex method you are using for your search. The reason is simple: you are doing things much too complicated. The good news is: you can do better
- you use minimax (most people use negamax),
- you deviate somehow from the well-known alpha-beta algorithm,
- your search is iterative (most people use a recursive search which is also much better regarding readability and less complex for beginners),
- and you do not store generated moves in a move list but immediately make each move that you just generated, which makes any kind of static move ordering much harder.
So there are a couple of things which could make your chess-programming life easier ...
A good answer to your specific question regarding alpha-beta and why two bounds are needed can be found at https://chessprogramming.wikispaces.com/Alpha-Beta:
Nevertheless, I would add that the explanation why we need a lower bound is not precise enough, for my taste. At the current node the lower bound "Alpha" (in case of Minimax it is "Alpha" for White and "Beta" for Black) is simply needed as upper bound for the opponent, while the upper bound is used directly to test for a cutoff: if a subtree returns a score that is beyond our current upper bound (in case of Minimax: >= Beta for White or <= Alpha for Black!) then we cut off all remaining subtrees since we know that we will return to our parent node with a score that is not better than the opponent's lower bound, so it will have no effect. To be able to do the same thing one ply deeper you use two bounds, one is saved for the opponent's viewpoint at the deeper node and the other is used at the current node.The situation becomes even more complicated, however, when we go to a search depth of 3 or greater, because now both players can make choices affecting the game tree. Now we have to maintain both a lower bound and an upper bound (called Alpha and Beta.) We maintain a lower bound because if a move is too bad we don't consider it. But we also have to maintain an upper bound because if a move at depth 3 or higher leads to a continuation that is too good, the other player won't allow it, because there was a better move higher up on the game tree that he could have played to avoid this situation. One player's lower bound is the other player's upper bound.
I hope this helps - maybe things will become clearer when you rewrite your program, and "do it the easy way" this time
Code: Select all
int AlphaBeta(Position pos, int alpha, int beta, int depth) {
if (depth == 0) return Eval(pos); // or QSearch(pos);
GenerateMoves(pos); // store moves in move list
for (all moves in move list) {
MakeMove(pos, move);
int score = -AlphaBeta(pos, -beta, -alpha, depth - 1);
UnmakeMove(pos, move);
if (score >= beta) return beta;
if (score > alpha) alpha = score;
}
return alpha;
}-
Sven
- Posts: 4052
- Joined: Thu May 15, 2008 9:57 pm
- Location: Berlin, Germany
- Full name: Sven Schüle
Re: Starting with quiescence search
In contrast to this, an iterative alpha-beta function with Minimax would perhaps look like this (not compiled, not tested!):Sven Schüle wrote:In fact recursive alpha-beta with Negamax is essentially not much more than this:Code: Select all
int AlphaBeta(Position pos, int alpha, int beta, int depth) { if (depth == 0) return Eval(pos); // or QSearch(pos); GenerateMoves(pos); // store moves in move list for (all moves in move list) { MakeMove(pos, move); int score = -AlphaBeta(pos, -beta, -alpha, depth - 1); UnmakeMove(pos, move); if (score >= beta) return beta; if (score > alpha) alpha = score; } return alpha; }
Code: Select all
int AlphaBeta_Iterative_Minimax(Position pos, int maxDepth)
{
enum Operation { GENERATE, MAKE, UNMAKE };
Operation op; // current state of state machine indicating what to do next
int ply; // distance to root node
int depth; // remaining depth until reaching full-width horizon
Move moveList[MAX_PLY][MAX_MOVES]; // move list per ply
int numberOfMoves[MAX_PLY]; // size of move list per ply
int moveIndex[MAX_PLY]; // index of current move in move list per ply
int alpha[MAX_PLY]; // Alpha bound per ply
int beta [MAX_PLY]; // Beta bound per ply
int score[MAX_PLY]; // current score per ply
// start at root
ply = 0;
depth = maxDepth;
alpha[ply] = -INFINITE;
beta [ply] = +INFINITE;
op = GENERATE;
while (not(op == UNMAKE and ply == 0)) {
switch (op) {
case GENERATE:
{
if (depth == 0) {
// leaf node, return evaluation to parent
score[ply] = Eval(pos); // or QSearch(pos)
op = UNMAKE;
} else {
GenerateMoves(pos, moveList[ply]);
moveIndex[ply] = 0;
op = MAKE;
}
break;
}
case MAKE:
{
if (moveIndex[ply] < numberOfMoves[ply]) {
// try next move from move list
MakeMove(pos, moveList[ply][moveIndex[ply]]);
++ply;
--depth;
op = GENERATE;
} else {
// no moves left in move list, return best score to parent
if (pos.side == WHITE) {
// Maximizer
score[ply] = alpha[ply];
} else {
// Minimizer
score[ply] = beta[ply];
}
op = UNMAKE;
}
break;
}
case UNMAKE:
{
++depth;
--ply;
UnmakeMove(pos, moveList[ply][moveIndex[ply]]);
// back up score returned from subtree
int tempScore = score[ply + 1];
if (pos.side == WHITE) {
// Maximizer
if (tempScore >= beta[ply]) {
// cutoff, return bound to parent
score[ply] = beta[ply];
op = UNMAKE;
} else {
if (tempScore > alpha[ply]) {
alpha[ply] = tempScore;
}
++moveIndex[ply];
op = MAKE;
}
} else {
// Minimizer
if (tempScore <= alpha[ply]) {
// cutoff, return bound to parent
score[ply] = alpha[ply];
op = UNMAKE;
} else {
if (tempScore < beta[ply]) {
beta[ply] = tempScore;
}
++moveIndex[ply];
op = MAKE;
}
}
break;
}
default:
break;
}
}
return score[ply];
}To be fair, the recursive Negamax non-pseudocode version with most required variables would be closer to this one (although "ply" is actually unused but will be required e.g. for mate scoring which is omitted here):
Code: Select all
int AlphaBeta(Position pos, int alpha, int beta, int ply, int depth) {
if (depth == 0) return Eval(pos); // or QSearch(pos);
Move moveList[MAX_MOVES];
int numberOfMoves = GenerateMoves(pos, moveList); // store moves in move list
for (int i = 0; i < numberOfMoves; i++) {
Move move = moveList[i];
MakeMove(pos, move);
int score = -AlphaBeta(pos, -beta, -alpha, ply + 1, depth - 1);
UnmakeMove(pos, move);
if (score >= beta) return beta;
if (score > alpha) alpha = score;
}
return alpha;
}