bob wrote:Zenmastur wrote:Think about these statements for a minute. If you find a transposition, then the ending position MUST be the same or it's not a transposition. This means the same side was on the move. You are reporting an odd difference between the depths of the current line of play and the line of play that lead to the position being placed in the transposition table. Therefore, one of the lines of play had to have white on the move and the other had to have black on the move. ALL transpositions must start from an identical position at some point in the past. Therefore the depth differences you're reporting can't be right! Why they're not right, I don't know, but in the end, I don't care, because I don't think it's central to this discussion!
That is simply incorrect. The difference in draft between two instances where a position was stored and where it was retrieved has NOTHING to do with side to move, which must always match. But A single ply reduction before either the store or the retrieval will change the distance by exactly 1 in terms of depth remaining to the end of the search, NOT the distance between the two nodes where the table is accessed.
When I store a position P at ply=10, wtm=1, draft=20 (we are doing a 30 ply search at the point where P is stored) I can then later match P with a remaining depth of 20, 21, 22, 23, 24, 25, ... giving differences of 0, 1, ...
The two MOST important pieces of data are the number of transposition and their depth. You can't discern either of these pieces of information from your data. So tell me, what good is this data. It is strong evidence that your claim about transpositions is wrong. Other than that, I see no use for the data.
bob wrote:But whatever you do, the part of the search in the last 5 plies or so is the majority of the search, so a small table out there is NOT going to be helpful. Might as well just not store the last 5 plies and save the overhead. I can certainly measure what that will do to search performance...
Well... a couple of thoughts.
5-plies is too many. You keep mentioning this number. I've determined there is little point to splitting it at 5-plies. With a 16Gb L2 TT and 5-plies directed at the L1 TT would support search sizes in excess of 75 trillion unique nodes. Seems a little excessive for most uses, although I must admit that I just completed a 30-trillion node search of a position, so it's possible that this could be useful.
I also thought about not storing them at all but I think that would be very bad for time to depth. You seem to think that what ever is stored in the L1 TT will be completely worthless. I don't!
I think it will catch a large number of transpositions. Most transpositions are short. Three and four ply transpositions are the most plentiful. I plan on catching most of these, even if they cross the L1-L2 TT boundary. But these aren't the most important one to catch as I have already pointed out.
By far the most important one's occur entirely within the L2 TT boundary. I plan on finding virtually
ALL of these. A highly over-subscribe TT will miss huge numbers off these as witnessed by the fact that Crafty's tree blows up by a factor of 10 or more when it runs into this condition.
One last comment, I suspect that if you put a "local" 4k, or 8k entry TT in crafty for use in the q-search “only” you would see a significant drop in time to depth in general. You said that 95% of the nodes in a middle game position come from the q-search. So why not make a small TT to catch the transpositions there?
I looked at doing this for crafty and concluded that it won't solve the over-subscribed TT problem. But crafty doesn't seem to suffer this fate until later than most engines due to a lack of probing in the q-search. But as fast as crafty is in raw NPS, it lags behind other engines in time to depth, because it doesn't probe in the q-search. So it would seem that the solution to this problem would be to place a small local TT to catch all the temporally local transpositions. This should improve time to depth by quite a bit I would think.
Everyone seems to over look the fact that small TT's work. The reason they work is that most transpositions are temporally local. (i.e. a position is more likely to be seen again in a few number of nodes than it is if a very large number of nodes have passed.) If transpositions weren't highly temporally local small TT's would be worthless.
Regards,
Zen[/quote]
bob wrote:I do not see any examples of your "dramatic tipping point" however. I only ran one test, but let fine70 run for an hour at 100M nodes per second with a 1gb hash table and it loped along at about the same branching factor forever. However, it does find a forced mate in 30-something which might or might not help.
You didn't find any evidence of a dramatic tipping point because you're trying very hard not to find it.
Can you see it now?
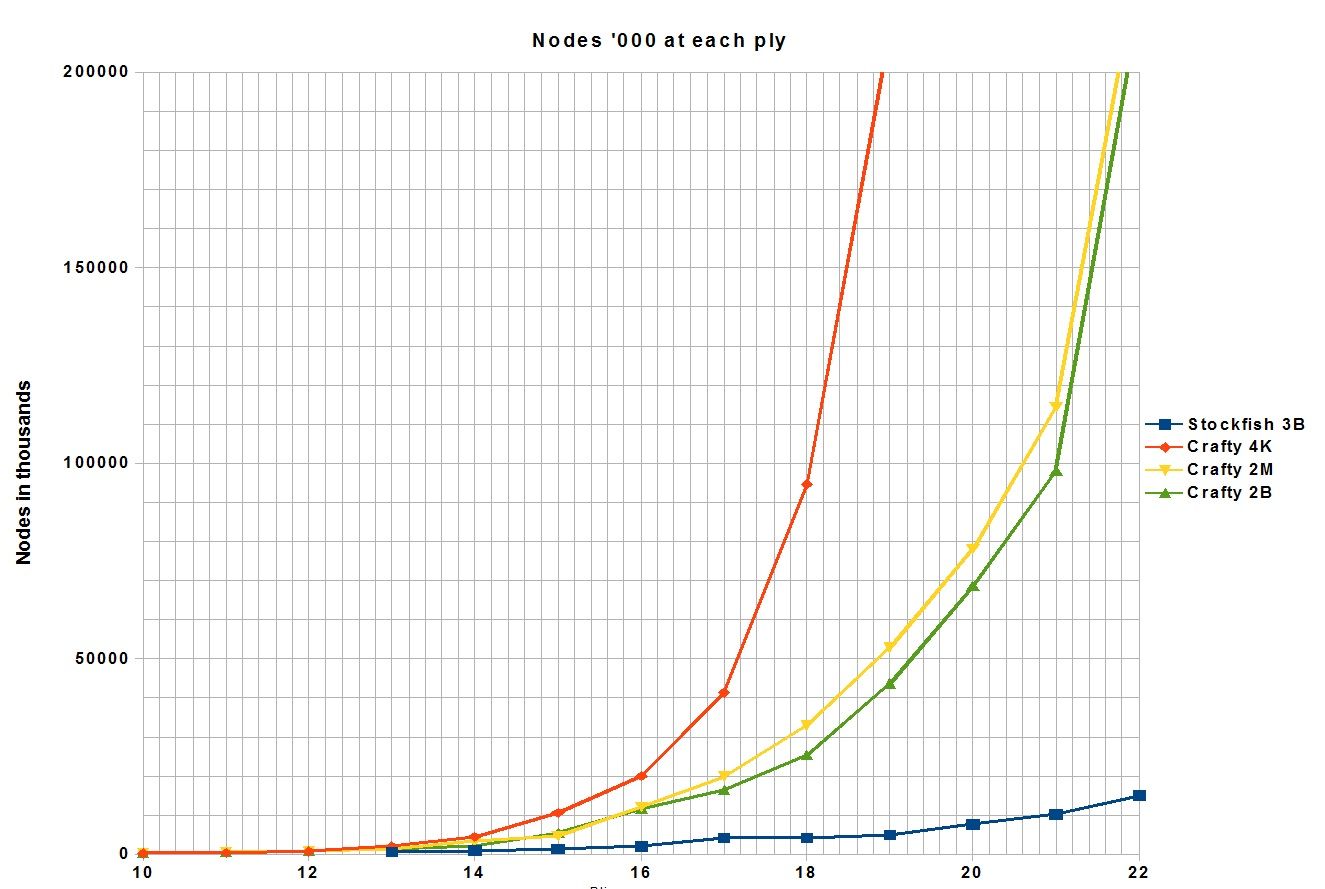
Crafty's EBF goes from 1.70 to 1.92 because the TT is over-subscribed. It doesn't get any more obvious than this.
This isn't from Fine#70 because Fine#70 is absolutely worthless for testing this!
First, it's a mate in 32. Until a pawn is captured, which should happen @ ply 27, there are only around 5,200 legal positions. After a pawn is captured the number of legal positions goes up, but most positions will be cut from the tree. White will see big gains from pushing the f pawn and capturing the d pawn. Black's king will try to stop the pawn pushes which constrains where it can go on the board. So, very few of the “possible” positions will actually be seen in the search tree.
[pgn]
[Event "Fine #70"]
[Site "?"]
[Date "1901.06.20"]
[Round "?"]
[White "Lasker, Emanuel"]
[Black "Reichhelm, Gustavus Charles"]
[Result "1-0"]
[WhiteElo "2600"]
[BlackElo "2400"]
[FEN "8/k7/3p4/p2P1p2/P2P1P2/8/8/K7 w - - 0 1"]
{[Stockfish 210616 64 BMI2] 104:M32}
1. Kb1 Ka8 2. Kb2 Ka7 3. Kb3 Ka6 4. Kc2 Kb7 5. Kc3 Kb6 6. Kd2 Kc7 7. Kd3
Kb6 8. Ke2 Kc7 9. Kf3 Kd7 10. Kg3 Ke7 11. Kh4 Kf6 12. Kh5 Kf7 13. Kg5 Kg7
14. Kxf5 Kf7 15. Kg5 Kg7 16. f5 Kf7 17. f6 Kf8 18. Kf4 Ke8 19. Kg4 Kf8 20.
Kg5 Kf7 21. Kf5 Kf8 22. Ke6 Ke8 23. Kxd6 Kf7 24. Ke5 Kf8 25. Ke6 Kg8 26.
d6 Kh7 27. d7 Kg6 28. f7 Kh5 29. d8=Q Kg4 30. f8=Q Kh3 31. Qg5 Kh2 32.
Qfh6# 1-0 [/pgn]
The critical positions are:
[d]8/6k1/3p4/p2P1pK1/P2P1P2/8/8/8 w - - 26 14
The first pawn is lost. Mate in 19.
[d]4k3/8/3pKP2/p2P4/P2P4/8/8/8 w - - 11 23
The second pawn is lost. Mate in 10.
[d]8/3P1P2/4K3/p6k/P2P4/8/8/8 w - - 1 29
Both pawns are going to queen. Mate in 4.
The sub-goals don't allow either side much wiggle room. So, with a well designed search you are going to see a only very small fraction of the “possible” legal positions. You pointed out that crafty could solve this problem with a 4K entry TT so it shouldn't be a big surprise that a 1B entry TT doesn't show a tree explosion regardless of how long the search is allowed to run.
I did my tests on this position.
[d]6k1/2p2rp1/p6p/P2b3N/5P2/7P/2p4K/2B1R3 b - - 0 41
This position is probably a forced mate with white winning just like fine#70.The difference is the mate is far enough away that it will only have an indirect affect on the search. There are enough pieces on the board that a reasonable sized TT can be oversubscribed. Of course the larger the TT the more time it takes to reach the oversubscribed condition and the longer the tests will take. I used TT's with 4,096 , 2 million, and 2 billion entries. I did several tests for each TT size and then averaged them. A different graph of the same data:
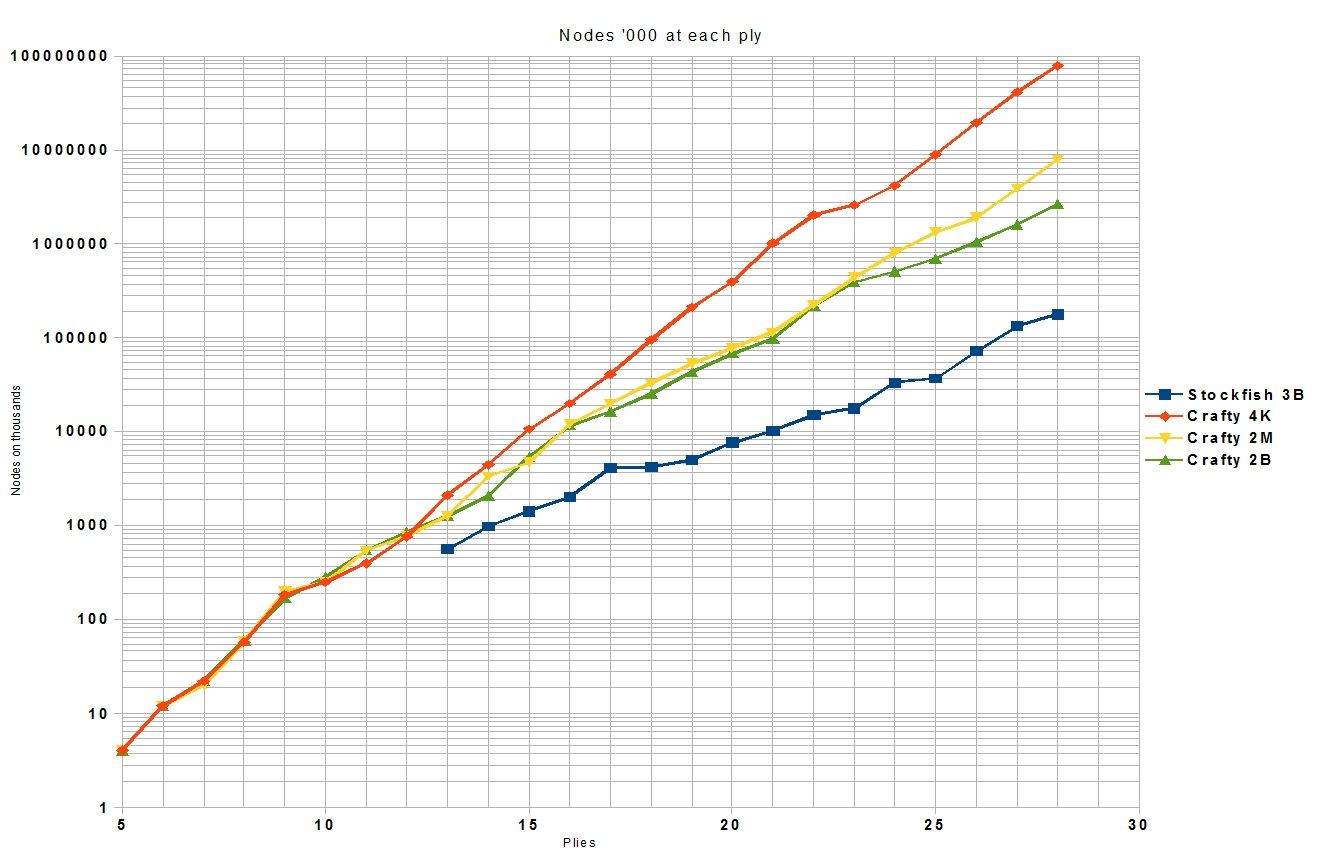
The data:
Code: Select all
K nodes K nodes K nodes K nodes
Ply Crafty4K Crafty2M Crafty2B SF3B
4 2 2 2
5 4 4 4
6 12 12 12
7 22 20 22
8 58 59 60
9 185 200 168
10 250 248 284
11 398 546 553
12 767 777 846
13 2,131 1,278 1,269 563
14 4,456 3,343 2,088 977
15 10,590 4,706 5,409 1,421
16 19,891 12,072 11,575 2,037
17 41,448 19,884 16,395 4,125
18 94,572 32,958 25,393 4,251
19 210,793 52,902 43,671 4,960
20 241,436 78,152 68,572 7,690
21 1,017,325 114,352 98,058 10,215
22 2,016,137 226,976 217,419 15,029
23 2,602,419 444,451 391,438 17,609
24 4,153,717 808,651 509,763 33,241
25 8,938,096 1,336,098 692,189 36,652
26 19,471,877 1,899,863 1,043,753 71,646
27 41,222,135 3,892,530 1,621,566 133,395
28 78,738,034 7,918,450 2,669,449 177,470
Regards,
Zen
Only 2 defining forces have ever offered to die for you.....Jesus Christ and the American Soldier. One died for your soul, the other for your freedom.

