I didn't spend much time on this so it's probably full of spelling, grammatical, factual, and logic errors. It's also based on using late model Intel server and desktop CPU's so the numbers given will likely change for other models or brands of CPU's.
A little more food for thought:
One of the advantage of splitting the TT into 2 parts, one large and one small is the speed advantage gained by not accessing main memory on every TT probe. If 4 kb pages are used a 8-gigabyte TT will occupy 2 million pages. These won't fit into a 1k entry L2 TLB. Since the probes into the TT will occur in pseudo-random locations almost all probes will miss the CPU caches and will require an access to main memory. The page lookup will miss the L1 DTLB and L2 TLB 99.9% of the time, which will require a page table walk. On a system with a four level page directory this will likely require 4 additional accesses to main memory before the virtual address can be translated to a physical address. Each of these is likely to take an additional 250-400 cpu cycles. On CPU's prior to Skylake there is only one page table miss handler available. There can be more than one outstanding page table miss. This means that there is no guarantee a TLB miss will be handled in a timely fashion and therefore a TT probe could wait several thousand cpu cycles before the required information is made available. This may not happen all the time but it must have been happening too often because Intel add a second page miss handler to Skylake CPU's plus increased the L2 TLB to 1.5K entries. In any case, decreasing the thrashing of the L2 TLB can only have a positive effect on engine performance regardless of the CPU used.
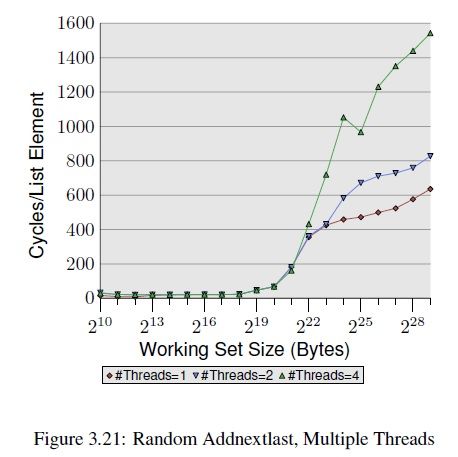
I have no clue why it isn't displaying this image and I don't really care, if you want to see I guess you'll have to go to the URL, sorry but I don't have the time to figure it out.
This graphic shows what happens to memory access times in multi-threaded applications access and modify an array elements in random order. This effect varies with array or working set size. When the array size exceeds the size of the CPU's caches access times go through the roof. So much so that they easily exceed the raw memory access time. This also shows the effect of TLB thrashing as the working set sizes causes the number of working pages to exceed the number that can be stored in TLB's . This graphic wasn't the one I had planned to use since the test was specifically design to show access times in single CPU multi-threaded applications based on limited memory bus speeds. But, I couldn't find the graph I was looking for and the working set sizes covered in this graph are large enough to exceed the capacity of most TLB (i.e. 512MB when using 4K pages requires 128K pages). So this graphic isn't perfect for what I'm using it for, but it does show that random access and modification to large arrays can take much longer than memory access times alone can explain. This graph should give a rough idea of what happens to access times of TT's as their size is increased.
By splitting the TT into a small cache-able part and a larger part the rate at which main memory needs to be accessed can be controlled to some extent. Even more importantly it seems, the TLB thrashing that takes place when using large TT's will be greatly mitigated. This will have a substantial impact on node processing.
There are some other considerations as well.
Giving each thread it's own L1 TT which IS NOT shared by other threads has several implications.
The first is that the cache entries “owned” by a a particular thread will follow that thread if it moves from one core to another. (i.e. it's interrupted so another process can run on its core, (hyper-threading should be turned off) when it's rescheduled that core may still be busy, in which case it will be run on a different core.) This could present a performance problem if this happen a lot. It's probably not a huge problem for a single CPU system because the data that's in the cores local L1 Data and L2 caches is also stored in the CPU's L3 cache. Further this data can be forwarded. So if the thread is moved to a different core, and not too much time has passed, the data that was in its L1 TT will likely still be found in the CPU's L3 cache and so won't require going to main memory when it's access from the new core. On a NUMA system the new core may be located on a different CPU. If the data is still in the original CPU's cache it can still be access but will create a lot of QPI traffic which is not good. If it's not in the L3 cache of the previous CPU it will still be available through main memory but access will be at main memory speed or worse until this info is cached on CPU the thread is executing on. So, it would be better to have the threads pinned to a particular core if possible.
A related issue is cache line state changes. A cache line on an a Haswell CPU has five states. They are Modified, Exclusive, Shared, Invalid and Forwarding (MESIF). If a cache line is Exclusive this means that no other cache has a copy of this data. Which means when you want to modify the data it can be done with out any delays. If it's shared a RFO to invalidate all other copies must be issued first. This effectively makes the cache-line Exclusive. An RFO must be broadcast on the CPU's local bus and on a NUMA system across the QPI links to other CPU's. This takes time and slows down the process. On a NUMA system the wait times can be excessive and the extra traffic between CPU's will not be appreciated. These buses are usually a major bottleneck and reducing traffic on them is highly desirable. So exclusive use of the L1 TT's saves additional time and helps keep the QPI links as lightly loaded as possible. The more CPU's in a NUMA system the more important it is to eliminate this un-needed traffic.
One of the slowest cache operations is the state change to Invalid. Issuing RFO's by the tens of millions per second is bad because every other cache in the system has to invalidate the line in question. If that cache line is needed again by any of the cores that had to invalidate it, it will have to be reloaded. This may create more QPI traffic in a NUMA system if the requesting and forwarding cores aren't on the same CPU. So a single RFO will likely create more QPI traffic than just that created by an RFO. This will have an impact on all NUMA machines. The more CPU's the system has the higher the impact.
Possible L1 TT sizes:
There are several reasons for wanting a larger L1 TT. One is to hold more entries so the TT is overwritten less often. A second reason is so the layout of the individual entries can be made as close as possible to the entries in the L2 TT. This allows more code re-use and less effort implementing it, if you are modifying an existing engine. And the last reason is so more, more accurate, and more useful information can be stored in the entries.
A natural questions to ask is how large can the L1 portion of a split TT be before it becomes a problem.
My answer is, I don't know for sure. It depends on the CPU(s) in use and the other code and data that will be accessed. From looking at the graphic above, I believe that, at a minimum, 64kb will still preserve a large fraction of its access time advantage compared to a large L2 TT and the number could be much higher, say 256kb. For numbers larger than this the advantages would rapidly begin to wain. The example I gave in the previous post where the L1 TT was only 4kb in size is probably a bit on the anemic side.
More and larger entries are possible. 2,048 or 4,096 entries of 16-bytes each seems easily doable. This would allow the L1 TT entries to closely mimic the data stored in the L2 TT in most engines. The larger number of entries would allow some information to be retained from a large number of previous 4-ply (or possibly larger) searches.
On a slightly different tack and this infor can be used on any TT not just a split TT:
The main purpose of a “tradition” TT is to save effort. How much effort is save depends on the size of the TT and it replacement policies. Most of the TT implementations I've seen uses depth of search and age as the metrics used in the replacement policy. I'm sure these are NOT the best metrics that can be found for this purpose. Someone, long ago, programming for a computer with more limited resources than most desktops have today, spent a little time to develop a TT replacement policy. It worked, and everyone copied it. Things have change since then, resource are more plentiful, but few have spent any time determining if the old replacement policies can be improved.
An example might help. When playing a game and the opponents last move was a pawn capture or promotion the number of pawns on the board is decrease. It's not possible to ever have more pawns on the board than the number from a previous ply. This means that any TT entry for a position that has more pawns than the current board position is completely worthless. It will never save any effort even if it remains in the TT until the end of the game. The depth of search (effort) used to produce the entry are irrelevant. Likewise, its age is irrelevant. If this information was stored explicitly in the TT entry, it would be an easy matter to determine if any entry is still useful. If it's not then it should be replaced before any other entry in that bucket. This way entries that are still useful will not be displaced in favor of those that have no possibility of ever being useful. Will this save effort? No doubt it will. The idea is sound, or as HGM would say “fundamentally correct”, but that doesn't mean it's useful. Will it be worth the 4 or 6 bits used to encode this information in the TT entries? I have no idea. I haven't tried it. It probably won't make a huge difference. It may not even be noticeable. The only way to know for sure is to test it.
Another example. Depth of search is needed to determine if the entry can be used in the current search. It's also often used as a metric in the replacement policy. The problem with this use is that not all n-ply search represent the same amount of effort. One 8-ply search might have required only 1,00 nodes to be searched while another may have required over 50,000 nodes. Current TT's don't contain enough information to make a distinction between the two. An entry that required searching 10,000 nodes that has been sitting unused is less valuable than an entry that took 3,000 nodes to produce but has produced 10 cut-offs. In order to make these distinctions requires more information than most TT entries contain. Further more, a node that took 1,000,000 nodes to produce and has cause 1,000 cut-offs can be discarded immediately if it has too many pawns.
There is one more aspect to placing more information in each entry and it's likely that it's more important. There is currently no quick and easy way to determine if one cache replacement policy is better than another. The current method could require 200,000 test games to determine which is better. This is a lot of work. With the proper information stored in each entry it should be easy enough to calculate the total number of nodes the TT represents and get an idea of how much effort has already been saved and therefore how effect the cache is likely to be in the near future. The procedure is quite simple.
1. Run the engine on a set of test positions
2. After the node count reaches 30 times the number of TT entries stop and do a node count and count of cut-off*Node count of all valid TT entries.
3. Change the replacement policy
4. Re-run the test positions with the new replacement policy.
5. Compare the results.
Depending on the size of the test suite the test can be run many times in less time than a set of test games can be played.
Increasing the size of each entry will affect the number of entries that can be stored in a TT of a given size. But it's easy enough to test if this is a worth while trade once you have a much more direct way to measure how the TT is performing. This testing method can even be used to evaluate the effects of the split TT I've been advocating.
Regards,
Forrest
Only 2 defining forces have ever offered to die for you.....Jesus Christ and the American Soldier. One died for your soul, the other for your freedom.
