Zenmastur wrote:I disagree. The purpose of a hash table is to get hits. One factor controlling the number of hits is the percentage of entries in the table that are occupied. If the TT is empty then it's completely worthless.
Wrong! You can get nearly 100% hits, on a table that is 99% empty. Because you are not picking a random place to look for entries, but you look for them in the same place as you store them. So how much larger the table is than you need doesn't really play a role at all.
So, I guess you need to define the word “performance” explicitly as your current usage seems counter-intuitive and vague.
HAsh-table performance = hit rate. Nothing vague about that. When you overwrite entries, probes that would otherwise have been hits now will be misses because the entry has disappeared. When they would not have been overwritten (e.g. because the table was infinitely large, or the replacement scheme was infinitely smart), you would hhave had those extra hits.
I think a TT is performing at it's best when it's completely full since this is when it has the highest probability of producing a hit when all other factors are held constant.
Wrong again. The number of necessary overwrites is determined by how full the table is. Not the hit rate. The larger you make the table for a given search, the emptier it will get, but the shorter the time needed to complete that search.
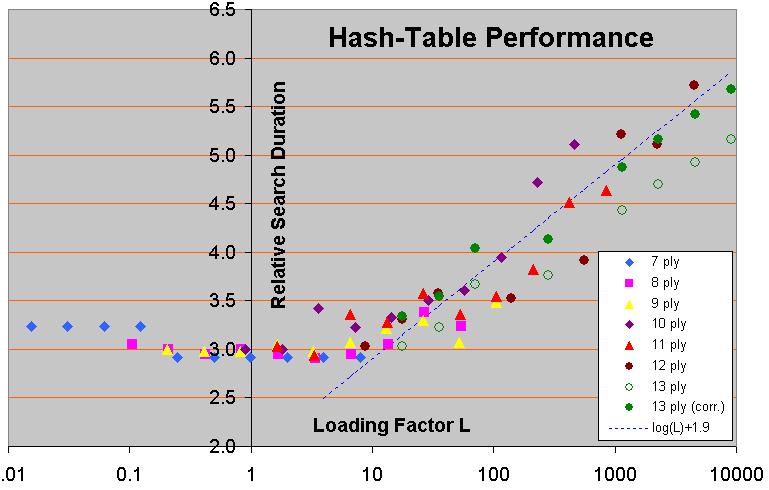
This graph of yours:
...
Seems to contradict your statement that “performance starts to fall when you start to overwirte entries". It's not clear how “loading factor” is defined as used in the graph but, assuming it is related to the number of unique stores in to a table of k entries in a linear way, (e.g. a loading factor of 10 represents 10 * k unique stores into a hash table of k entries),
Wrong assumption. It does not represent unique stores but number of tree nodes of an unpruned tree.
... then it looks to me like the performance stays about the same over a wide range of “loading factors”. i.e. from ~ 0.5 to ~5. This contradicts your 1/e example.
This is because the number of unique positions is about an order of magnitude smaller than the total number of positions in the tree. The number of unique positions is hard to determine, however.
Furthermore, note that the 1/e overwrite fraction is for an always-replace table. Even with buckets of 4 and only preferring storing in empty slots over filled ones you will have only very few overwrites before the filling fraction gets close to 100%. And the graph is for a much smarter replacement scheme.
A “significant performance drop” as compared to what? An infinite size table?
Compared to a situation without overwrites, which can always be achieved by a large-enough table, and helped by smarter replacement.
I doubt this is true and your graph certainly doesn't support this conclusion.
The graph clearly shows that if you make the same search in a smaller table (i.e. at larger overload), the search time goes up. After you reach the point where the tree does not fit in the tableanymore.
In order for there to be any degradation in performance a location has to be referenced at least 3 times. Once to place an entry in it, once to overwrite it, and once to reference the original data and this has to happen in that order. If the data in the cell is referenced and produces a hit before its over-written no performance is lost. At least not until another (fourth) reference to that location is made.
Yeah, so?
I think I'll stand by my previous assertion that the number of entries in the hash table is the controlling factor here and not the number of transpositions, since if the transpositions were the cause of this effect the cache hit rate would be VERY high.
Not sure at all what cache-hit rate has to do with any of this. But besides that, your conclusion about it also seems wrong. The cache is quite small compared to the table, and not able to catch most transpositions.
Besides, what engine uses a full width search without Alpha-Beta which is what this statement seems to imply.
I am not sure why you think this implies such a thing. If on average every unique position occurs 10 time in the perft tree, why would it be different in an alpha-beta search tree? Do you know any particular reason why the alpha-beta tree would not be a representative sampling of the perft tree, but would discriminate against duplicats?