Lasse Hansen wrote:I use an always replace startegy, but split the hash table in 8 parts, as in
HashTable[wtm][depth]. This way deep entries are kept much longer than when
using a flat table.
I also found that it works best if you reserve approximately equal numbers of entries for each depth ('draft'). I usually implement this only in a statistical way:
in a depth-preferred table you will start to push out the lowest depths as the table fills. So I keep a histogram of the distribution of depths the depth-preferred table contents. Any depth that is present more than the lowest depth is then declared 'over-represented', and will be replaced when the primary probe maps to it (and the new position is not already elsewhere in the hash bucket).
Otherwise I replace the lowest depth of depth-preferred entries, if the new entry has a larger depth. Otherwise, the new entry goes to the always-replace slot of the hash bucket.
As the depth distribution quickly evolves to one where all depths are equally present, the turn-over of each depth will be controlled by how fast entries of that depth are produced. So larger depths automatically survive much longer than smaller depths.
with 5 seconds you are lucky indeed with that strategy. With always replace you would of course be much faster.
Mine old laptop tells me
info depth 26 seldepth 28 time 16 nodes 26094 pv a1b1 a7b7 b1c1 b7c8 c1d2 c8d7 d2c3 d7c7 nps 1630874 score cp 183 hashfull 0 tbhits 0
bestmove a1b1 ponder a7b7
info time 329 nodes 106666 nps 324212
I use a bucket system with 4 buckets. If I want to store a position and already find it in one of the buckets it is replaced (always).
If not I look for a bucket with an old entry (not from current or previous search). If I found one it goes in there.
Otherwise I store it in the bucket that seems to contain the least useful data (depending on age, depth and node type).
To keep an even distribution over the buckets I XOR 2 upper bits from the hash key when I loop over the buckets. This ensures also that a position has a good chance to be found in the first bucket I look into.
Seems to work Ok for me.
Thomas...
OK, I grouped entries by buckets of 4, and replicated the Stockfish replacement strategy. The results are rather unclear:
+ the fine #70 position is solved *much* faster, which is good, but irrelevant (it's just a particular position, which says nothing in general)
- in self testing, after 2000 games in 6"+.1" with 1 MB of Hash, I didn't see an improvement. In fact, even a regression, though it's within the error bar
So I kept it anyway, as everyone else does this, and it's possible that it kicks in at long time controls (although this is pure speculation and I haven't seen any hard proof of it).
Theory and practice sometimes clash. And when that happens, theory loses. Every single time.
How many nodes/sec does your engine do? Do you really think that this would overload a 1MB hash table? (Considering that many of the nodes in your tree counted towards the nps will be transpositions, or researches of nodes that were visited earlier, at different depth, or no longer applying bounds.)
If the hash table is large enough to contain the entire tree, you should not be surprised that you don't see any effect of the replacement algorithm...
How many nodes/sec does your engine do? Do you really think that this would overload a 1MB hash table? (Considering that many of the nodes in your tree counted towards the nps will be transpositions, or researches of nodes that were visited earlier, at different depth, or no longer applying bounds.)
If the hash table is large enough to contain the entire tree, you should not be surprised that you don't see any effect of the replacement algorithm...
1 MB = 65,536 entries of 16 bytes
average speed > 1 Mnps. so the effect should start to kick in already at this time control / hash size. and on my bench run I noticed quite a significant *increase* in node count, when I introduced the patch (it searches 16 positions at depth 12 in a total of 8 sec).
anyway, i really cant be bothered to play 2000 games in 60"+1", if that's what it takes to measure anything (if at all).
Theory and practice sometimes clash. And when that happens, theory loses. Every single time.
Always overwrite entrys of an older table genereration.
And if the table generation is the same then:
Lowerbound and exact will always overwrite an existing entry if the depth >= existing depth or the existing entry is an upperbound.
Upperbounds will only overwrite upperbounds with lesser or equal depth.
So upperbounds wil never overwrite lowerbound or exact entrys from the same table generation.
I don't think this works very well. One needs to ALWAYS store an entry, period. The only question is, what gets overwritten, not IF something gets overwritten. Otherwise you can "outsearch" the TT and reach a point where it doesn't help at all because you refuse to overwrite, and the stuff you are trying to store is important for future efficiency.
I make multiple tests but in every case that HashStore() is called, I store that entry, period...
Bob, the way how i read Joost's posting is that this isn't a brainwave type HGM, yet that this is something that actually works for him.
Also it basically says that in some huge amount of cases, which will be some percentage close to 99% i'd guess, he's overwriting.
So you're disagreeing here now about that 1%?
I don't know that it is just 1%. If I complete a search and fail low, storing that is certainly useful information, and storing fail low positions happens at every other ply along a path.
I think you have to always store the current position, and simply try to choose intelligently what you are going to replace.
I'm not sure i agree with that, even though Diep's policy is to always overwrite as well (could be there is 1 or 2 cases where this doesn't happen but odds of that are real tiny, garantueed a lot smaller than 1%).
Basically we can safely assume we all do several probes. Joost describes that he always overwrites entries from previous searches. So we speak already about the case that all slots have been filled with entries from THIS search AND both conditions true:
I) all slots filled with (lowerbound OR upperbound > this depth)
What are odds of this occuring?
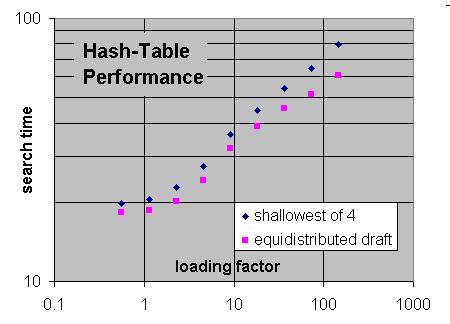
We know Joost usually plays faster time controls AND has a lot of RAM and might not store qsearch to hashtable, so loading factor is not spectacular high.
Lasse Hansen wrote:I use an always replace startegy, but split the hash table in 8 parts, as in
HashTable[wtm][depth]. This way deep entries are kept much longer than when
using a flat table.
I also found that it works best if you reserve approximately equal numbers of entries for each depth ('draft'). I usually implement this only in a statistical way:
in a depth-preferred table you will start to push out the lowest depths as the table fills. So I keep a histogram of the distribution of depths the depth-preferred table contents. Any depth that is present more than the lowest depth is then declared 'over-represented', and will be replaced when the primary probe maps to it (and the new position is not already elsewhere in the hash bucket).
Otherwise I replace the lowest depth of depth-preferred entries, if the new entry has a larger depth. Otherwise, the new entry goes to the always-replace slot of the hash bucket.
As the depth distribution quickly evolves to one where all depths are equally present, the turn-over of each depth will be controlled by how fast entries of that depth are produced. So larger depths automatically survive much longer than smaller depths.
Most play rapidchess at best. Most do not store qsearch. Even with 5 million nps means you store 20% at best = 1 million nps a second to hashtable.
Most use a hashtable of gigabytes nowadays. 2GB is common.
With 16 bytes an entry, which is more than most use, that's 131 million entries.
You'll need to start with 131 seconds to fill it.
To get to laoding factor 100 you need to search for a week or 2?
For a theoretic loading factor of 1.0
So for each search loading factor 100 you describe in table here takes
Always overwrite entrys of an older table genereration.
And if the table generation is the same then:
Lowerbound and exact will always overwrite an existing entry if the depth >= existing depth or the existing entry is an upperbound.
Upperbounds will only overwrite upperbounds with lesser or equal depth.
So upperbounds wil never overwrite lowerbound or exact entrys from the same table generation.
I don't think this works very well. One needs to ALWAYS store an entry, period. The only question is, what gets overwritten, not IF something gets overwritten. Otherwise you can "outsearch" the TT and reach a point where it doesn't help at all because you refuse to overwrite, and the stuff you are trying to store is important for future efficiency.
I make multiple tests but in every case that HashStore() is called, I store that entry, period...
Well, I tried many combinations, and this works the best for my engine.
It's possible that this will be different for Crafty.
I don't have a separate hashtable for the PV, this scheme keeps the PV alive. If you have a big enough hashtable it's not that critical anyway.
hgm wrote:So what is your point? That if the hash table is big enough, replacement is no issue? That is pretty obvious, not?
As to your arithmetic:
131 sec ~ 2 min.
200 min ~ 3hours. Not 2 weeks.
It is not at all uncommon that people analyze positions for hours, for correspondence Chess...
Yes and other than Diep all engines are really optimized for correspondencechess as they incorporate big knowledge and do many probes in the hashtable and use more than 64 bits in hashtable to avoid collissions.
Also in all their testing at home they test real slow time controls and do not mess up in search when getting to big depths.
Really correspondence optimized you know!
thumbs up!
In the meantime why don't you continue your work at winboard to allow faster time controls than 1 second entire game?