From the viewpoint of the hash slot, having a slot store a single d=20 entry on which you get 1 hit does less good than a slot that stored 1000 different d=10 entries on which you get 5 hits each. (As with effective branhing ratio 2, d=20 searches have a 1000 times bigger tree than d=10 searches, and d=10 probes are 1000 times more common than d=20 probes.) So it is in fact not obvious that preferring high drafts buys you anything at all.
A much more important effect is that the distribution of hash hits on a given position decreases in time. Immediately after the entry was created, there is a large probability it wil be quickly revisited, through a transposition of recent moves (i.e. moves close to the leaves). After that you become dependent on transpositions with moves closer to the root, and such moves have a much slower turnover.
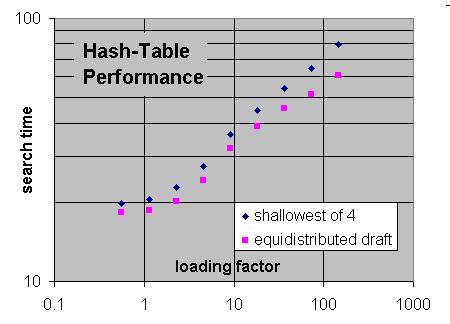
This is why TT slots are used much more effectively by storing recently made entries in them. And this is why equi-distributed draft replacement works so much better than other replacement schemes, when space gets really tight.