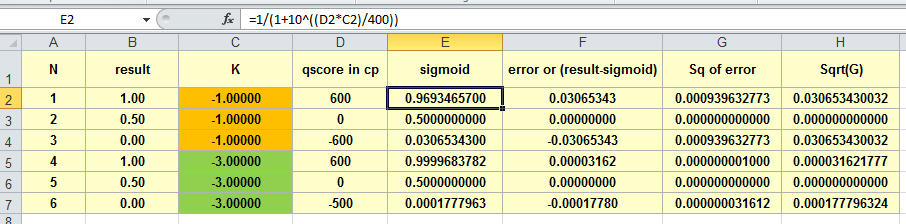
i just read the chessprogramming article about Texels tuning algorithm and found the following part which i do not understand.
Code: Select all
Sigmoid(s)=1/(1+10^(-K/400))
K is a scaling constant.
Compute the K that minimizes E. K is never changed again by the algorithm.
My error computation attempts only pass an evaluation score to the sigmoid function. So, if i get the result of 0.6 i can square the difference to 0.0/0.5/1.0 or just another reference value computed by the sigmoid function.
So, how does it help, if i just want the minimized sum of squared errors ?
Thanks in advance.