Current data - threads-nps efficiency up to 32 threads
Moderators: hgm, Rebel, chrisw
-
fastgm
- Posts: 818
- Joined: Mon Aug 19, 2013 6:57 pm
-
matthewlai
- Posts: 793
- Joined: Sun Aug 03, 2014 4:48 am
- Location: London, UK
Re: Current data - threads-nps efficiency up to 32 threads
I would recommend looking at time to fixed depth instead (across a few different positions, and take the average).
Parallel searches make the search tree bigger.
2x NPS is very bad if the search tree is 3x the size (to reach the same depth).
Parallel searches make the search tree bigger.
2x NPS is very bad if the search tree is 3x the size (to reach the same depth).
Disclosure: I work for DeepMind on the AlphaZero project, but everything I say here is personal opinion and does not reflect the views of DeepMind / Alphabet.
-
Laskos

- Posts: 10948
- Joined: Wed Jul 26, 2006 10:21 pm
- Full name: Kai Laskos
Re: Current data - threads-nps efficiency up to 32 threads
No, TTD is not an universal measure. Andreas to 16 threads already performed the REAL strength measure with 3,000 _games_ each datapoint. Now he is looking for the limiting value of effective speed-up for these engines. Effective speed-up will never be larger than NPS speed-up.matthewlai wrote:I would recommend looking at time to fixed depth instead (across a few different positions, and take the average).
Parallel searches make the search tree bigger.
2x NPS is very bad if the search tree is 3x the size (to reach the same depth).
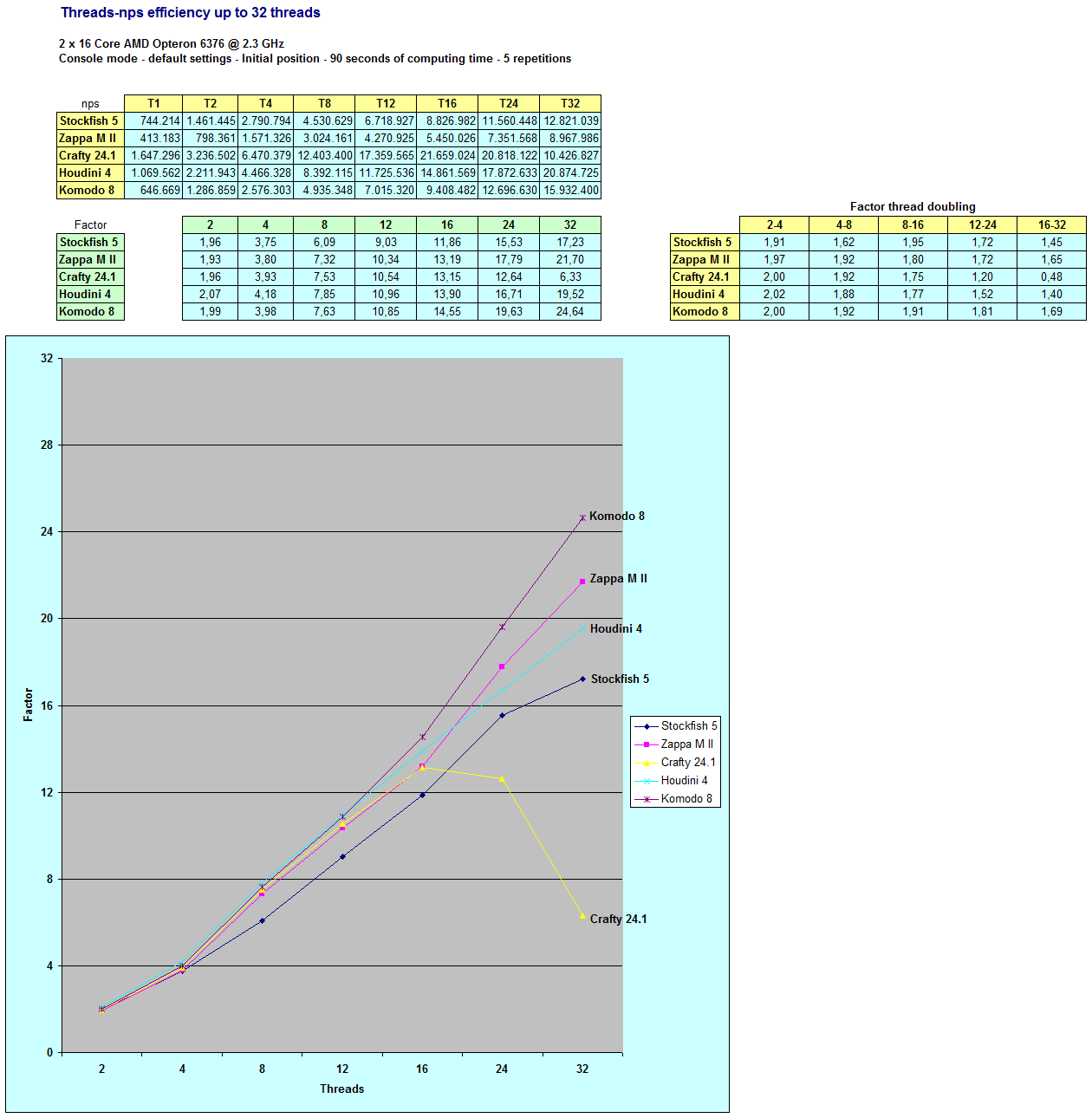
Something strange happens with Crafty.
-
Mark
- Posts: 216
- Joined: Thu Mar 09, 2006 9:54 pm
Re: Current data - threads-nps efficiency up to 32 threads
What in the world happened to Crafty >16 cores??
-
bob
- Posts: 20943
- Joined: Mon Feb 27, 2006 7:30 pm
- Location: Birmingham, AL
Re: Current data - threads-nps efficiency up to 32 threads
Laskos wrote:No, TTD is not an universal measure. Andreas to 16 threads already performed the REAL strength measure with 3,000 _games_ each datapoint. Now he is looking for the limiting value of effective speed-up for these engines. Effective speed-up will never be larger than NPS speed-up.matthewlai wrote:I would recommend looking at time to fixed depth instead (across a few different positions, and take the average).
Parallel searches make the search tree bigger.
2x NPS is very bad if the search tree is 3x the size (to reach the same depth).
Something strange happens with Crafty.
Something REALLY strange. I have never seen a case where the NPS drops when adding CPUs. Not ever. I've seen cases where the speedup certainly falls off.
Also, what kind of machine does he have. Those NPS numbers look REALLY low for Crafty. My 2 year old macbook pro with a dual i7 at 2.0ghz runs Crafty at 5M nodes per second on one CPU. I use a 12 core box to play chess all the time on ICC, has two Intel 5650 6-core processors running at 2.67 ghz. No hyper threading or turboboost. I see 40-50M nodes per second with 12 cores on that machine, which is about 4 years old or so...
No idea what 2x16 box would deliver that kind of poor performance using Crafty...
This an excerpt from a longish game played on ICC...
time=1:25(89%) n=4283303045(4.3B) fh1=81% nps=50.1M 50=0
chks=199.2M qchks=492.2M sing=413.1K/104.5K fut=1.2B pred=35
LMReductions: 1/52.4M 2/23.3M 3/8.0M 4/759.3K 5/4.4K
null-move (R): 3/83.8M 4/7.1M 5/284.7K 6/7.6K
splits=511.3K aborts=102.9K data=25% probes=0 hits=0
Also it would be interesting to know which operating system and compiler. I've been seeing some pretty strange stuff with gcc of late. For example, compile Crafty as one large source file, get nps=24M. Compile individual files, nps=50M. After making some changes, this can invert. And then there is the sometimes profiled code is faster, sometimes it is not. Never see that with Intel's compiler...
Last edited by bob on Sat Oct 25, 2014 2:05 am, edited 1 time in total.
-
bob
- Posts: 20943
- Joined: Mon Feb 27, 2006 7:30 pm
- Location: Birmingham, AL
Re: Current data - threads-nps efficiency up to 32 threads
Absolutely unknown. I have one 24 core box around that I tested on and could not produce that effect at all. The cores add to the NPS in a pretty linear way, although the parallel speedup doesn't climb as quickly as the NPS.Mark wrote:What in the world happened to Crafty >16 cores??
-
fastgm
- Posts: 818
- Joined: Mon Aug 19, 2013 6:57 pm
Re: Current data - threads-nps efficiency up to 32 threads
Hello, Mr. Hyatt,
yes, the behavior of Crafty is really strange!
The System is a 32-way dual 16 core AMD Opteron 6376, Mainboard ASUS KGPE-D16 with 8 x 4 GB 1600 MHz DDR3.
OS is Windows 7 Professional 64 Bit.
Crafty reports: System is NUMA. 4 nodes reported by windows
For the test I used the "official" Crafty version "crafty-24.1-x64-sse3.exe" from http://www.kikrtech.com/
Best regards,
Andreas Strangmüller
yes, the behavior of Crafty is really strange!
The System is a 32-way dual 16 core AMD Opteron 6376, Mainboard ASUS KGPE-D16 with 8 x 4 GB 1600 MHz DDR3.
OS is Windows 7 Professional 64 Bit.
Crafty reports: System is NUMA. 4 nodes reported by windows
For the test I used the "official" Crafty version "crafty-24.1-x64-sse3.exe" from http://www.kikrtech.com/
Best regards,
Andreas Strangmüller
-
bob
- Posts: 20943
- Joined: Mon Feb 27, 2006 7:30 pm
- Location: Birmingham, AL
Re: Current data - threads-nps efficiency up to 32 threads
4 nodes looks wrong. A node = one physical core with one shared memory (local) bank. Is your bios set to NUMA or SMP? Or whatever they call it now. Most AMD systems with more than one chip allow you to allocate memory with consecutive addresses on a single node. IE if you have 4 nodes and 4 gigs, node 0 gets addresses 0-1gig, node 1 gets addresses 1-2 gigs and so forth. If you put it in SMP mode, then node 0 gets page 0, node 1 gets page 1, interleaving the pages across all the nodes. Idea here is that for non-numa-aware programs, that spreads memory addresses (like the hash table) uniformly across the nodes, where it would be better to have consecutive addresses on a single node if the program knows how to allocate and use memory correctly. I'll try to look up that CPU and MB to see exactly what it does, NUMA-wise. But 4 nodes seems a bit odd, every AMD box I have used reported nodes = chips, which for some machines was nodes = cores when we had 1 core per chip.fastgm wrote:Hello, Mr. Hyatt,
yes, the behavior of Crafty is really strange!
The System is a 32-way dual 16 core AMD Opteron 6376, Mainboard ASUS KGPE-D16 with 8 x 4 GB 1600 MHz DDR3.
OS is Windows 7 Professional 64 Bit.
Crafty reports: System is NUMA. 4 nodes reported by windows
For the test I used the "official" Crafty version "crafty-24.1-x64-sse3.exe" from http://www.kikrtech.com/
Best regards,
Andreas Strangmüller
more after some research.
-
bob
- Posts: 20943
- Joined: Mon Feb 27, 2006 7:30 pm
- Location: Birmingham, AL
Re: Current data - threads-nps efficiency up to 32 threads
If you ever have time, could you run crafty with 1 cpu, 2, 4, 8, 16 and 32 and use the bench command, and send me the log file? And the final question, how long did the test you used run? Fractional second tests can certainly produce all sorts of weird numbers.fastgm wrote:Hello, Mr. Hyatt,
yes, the behavior of Crafty is really strange!
The System is a 32-way dual 16 core AMD Opteron 6376, Mainboard ASUS KGPE-D16 with 8 x 4 GB 1600 MHz DDR3.
OS is Windows 7 Professional 64 Bit.
Crafty reports: System is NUMA. 4 nodes reported by windows
For the test I used the "official" Crafty version "crafty-24.1-x64-sse3.exe" from http://www.kikrtech.com/
Best regards,
Andreas Strangmüller
-
Modern Times
- Posts: 3546
- Joined: Thu Jun 07, 2012 11:02 pm
Re: Current data - threads-nps efficiency up to 32 threads
It is AMD running at a low clock of 2.3GHz. With this generation of AMD CPU, performance per core is quite low, but you have lots of them. On the desktop they run at 4GHz+ and people overclock beyond that, and then performance is good, but on a server you can't do that.bob wrote:Also, what kind of machine does he have. Those NPS numbers look REALLY low for Crafty. My 2 year old macbook pro with a dual i7 at 2.0ghz runs Crafty at 5M nodes per second on one CPU.
I doubt there is anything wrong with his BIOS settings, some of those other engines are scaling very well indeed.