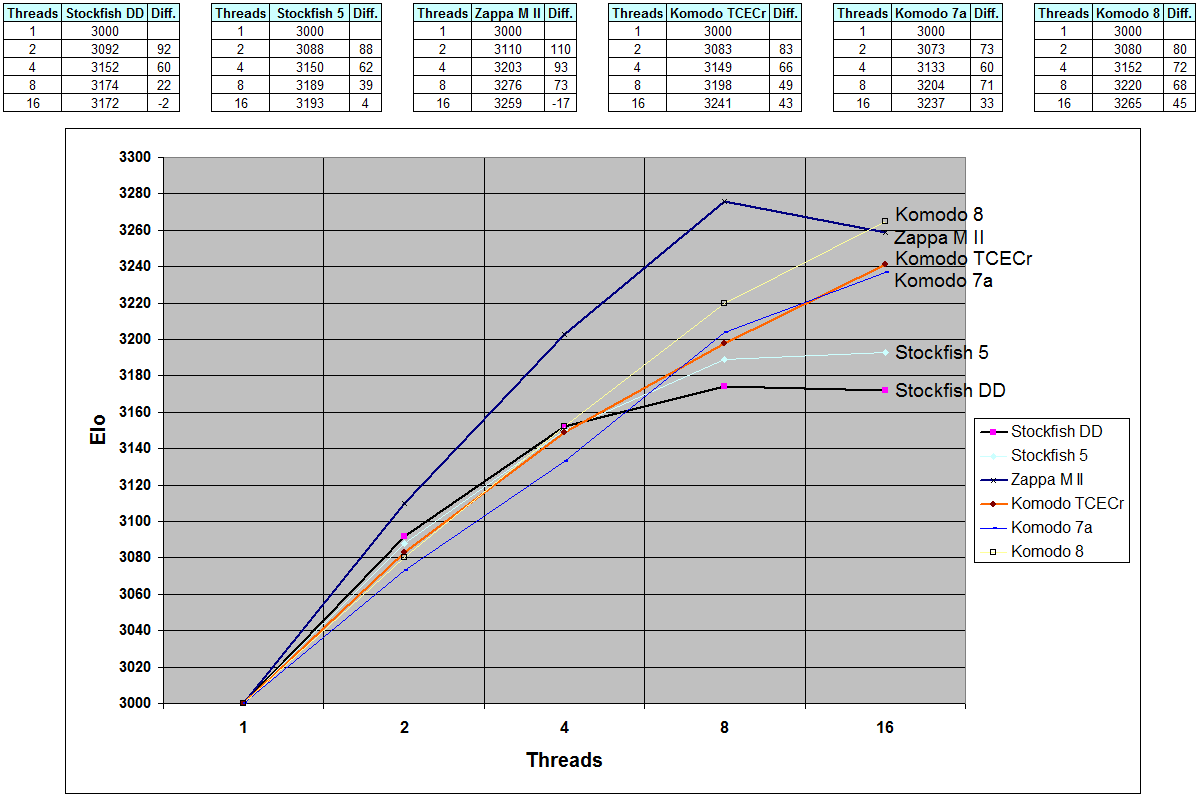
Laskos wrote:Thank you, Andreas, very important tests. I imagine that testing engines on 16 threads is time consuming as hell.
You bust to pieces two of Bob Hyatt loud claims:
1) That Komodo implementation of SMP is "buggy", "quick and dirty", and so on. It seems one of the best to 16 threads.
2) That formula for SMP improvement withe the number of cores is linear. He gave "his" mastermind formula (N-1)*0.7 + 1, IIRC. Nothing linear here, not for a single engine.
When I will reply to Bob, I will quote your results.
Thanks again.
Didn't bust a THING I said. I said "if a search "widens the tree", which is YOUR term, that it has a bug that can be fixed." I said nothing more or nothing less. If a program plays stronger using N cpus to a fixed depth than it plays using one CPU, it has a bug that can be fixed to improve the performance of the single-thread version. That YOU don't understand that simple statement doesn't mean you can "shoot it to pieces". It just shows YOU do not understand the issues of parallel search. This ranks right up there with the super-linear speedup nonsense that comes up on occasion. It does NOT happen unless the sequential program has a problem that can be fixed. period.
And will you please stop misquoting what I said about that speedup formula. I did NOT say it was a highly accurate fit to the observed data. I said it was a fairly accurate estimate that is quite easy for anyone to compute. Nothing more, nothing less. And it is pretty accurate through 16 cores for sure, and even beyond but with less testing data to support it. When you grow up and learn to read, you might understand the term "linear approximation" or "simple approximation" etc.
If you look back through old CCC archives, you can see ANOTHER discussion about this formula. Martin Fierz took a bunch of 1/2/4/8 core test data I ran for him and compared it to my formula. His discovery was that my formula was too pessimistic. But I didn't develop it to be optimistic or pessimistic. Just something that approximates the speedup for a rough estimate.
please...
And for the record, my approximation had NOTHING to do with predicting Elo. Just raw SMP speedup measured time to depth.