Hi everyone,
I want to improve my transposition table. Right now I'm using the most basic form of a TTable (one bucket per index and an always replace strategy). I want to implement chaining (4 buckets per index) and a better replacement strategy.
Would you recommend a 2D array of size [table size][4], or just storing entries at at (index, index+1, index+2, index +3)? I'm trying to avoid the use of linked lists.
Also, what are the replacement strategies that you guys use?
Any help is appreciated. Thanks in advance.
Transposition table chaining and replacement strategy
Moderators: hgm, Rebel, chrisw
-
raccoon
- Posts: 6
- Joined: Sat Jul 26, 2014 9:53 am
-
cetormenter
- Posts: 170
- Joined: Sun Oct 28, 2012 9:46 pm
Re: Transposition table chaining and replacement strategy
I actually just made this transition myself. It was a pretty nice improvement in Nirvana and significantly improved its time to depth.
For a 4 bucket system it seems like the go to is to use a 1-d array. Then you use either the upper or the lower 32 bits of your hash to find a starting index in your table. You then loop over the four entries located at and directly after your starting index. Then you can compare the other half of your hash key to the key that is saved in the table.
For replacement Nirvana first looks to see if the current entry has the same key as the entry that is being saved. If so it replaces it. Also if the entry is empty then it is replaced. If neither of these conditions are true then it is assumed that the first entry is the "worst". The subsequent entries then become the worst entry if they were produced by a search earlier in the game than the current worst or have a lower depth. This allows for the hash table to be filled with mostly entries from the current search that are of a high depth.
Sample Code from Nirvana:
For a 4 bucket system it seems like the go to is to use a 1-d array. Then you use either the upper or the lower 32 bits of your hash to find a starting index in your table. You then loop over the four entries located at and directly after your starting index. Then you can compare the other half of your hash key to the key that is saved in the table.
For replacement Nirvana first looks to see if the current entry has the same key as the entry that is being saved. If so it replaces it. Also if the entry is empty then it is replaced. If neither of these conditions are true then it is assumed that the first entry is the "worst". The subsequent entries then become the worst entry if they were produced by a search earlier in the game than the current worst or have a lower depth. This allows for the hash table to be filled with mostly entries from the current search that are of a high depth.
Sample Code from Nirvana:
Code: Select all
tt_entry * hashe = &tt[((U32)BOARDHASH) & TTMASK];
tt_entry * worste = hashe;
for (int i = 0; i < ClusterSize; hashe++, i++)
{
if (hashe->hash == (BOARDHASH >> 32))
{
worste = hashe;
break;
}
if (!hashe->hash)
{
TTWRITES++;
worste = hashe;
break;
}
if (hashe->Generation < best->Generation)
worste= hashe;
else if (hashe->Depth < best->Depth )
worste = hashe;
}
//Replacement code goes here
-
hgm

- Posts: 27796
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Transposition table chaining and replacement strategy
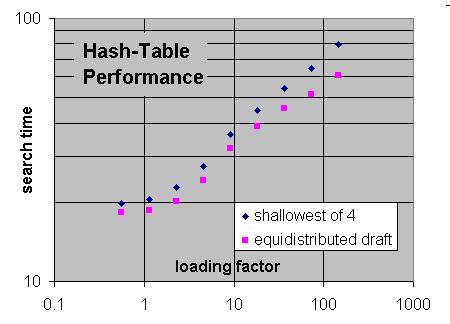
The scheme that seems to work best tries to keep the distribution of drafts in the table as even as possible. So rather than replacing the entry in the bucket with the lowest draft, you can replace the entry with the draft that is already most present in the table as a whole. (This would of course require you to keep counters on the presence of each draft.) So what I usually do is check if the primary entry the position maps to contains an draft that is 'over-represented' (i.e. occurs more than draft 1), and if so, replace that. Otherwise, replace the shallowest in the bucket. This prevents the higher drafts from conquering the table, as they would when they are never replaced, pushing the lower drafts completely out of it.
-
AlvaroBegue
- Posts: 931
- Joined: Tue Mar 09, 2010 3:46 pm
- Location: New York
- Full name: Álvaro Begué (RuyDos)
Re: Transposition table chaining and replacement strategy
I am trying to interpret hgm's plot, but I don't know what "loading factor" means. Care to explain?
-
hgm
- Posts: 27796
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Transposition table chaining and replacement strategy
'Loading factor' is the number of nodes visited in the tree divided by the size of the table (in entries).
-
AlvaroBegue
- Posts: 931
- Joined: Tue Mar 09, 2010 3:46 pm
- Location: New York
- Full name: Álvaro Begué (RuyDos)
Re: Transposition table chaining and replacement strategy
I thought of that possibility, but then it seems like too much of a coincidence that the pairs of points seem to have the exact same horizontal coordinate. For instance, the pair of points farthest to the right have a search-time ratio of about 80/60, so "shallowest 4" took 33% more time than "equidistributed draft". Presumably both runs used the same size of hash tables and had similar speed on nodes-per-second, so the horizontal coordinate should also be about 33% more for one than the other, but I don't see it.hgm wrote:'Loading factor' is the number of nodes visited in the tree divided by the size of the table (in entries).
-
raccoon
- Posts: 6
- Joined: Sat Jul 26, 2014 9:53 am
Re: Transposition table chaining and replacement strategy
Thanks for your replies.
@ Thomas
From what I understand, you are only storing the upper 32 bits of the zobrist key in the transposition table. Does this lead to more collisions than if you were to store the full key? Are there any advantages besides reduced memory?
@ H.G.
I've heard this before but I don't really understand why entries with higher depth pollute the table. If you had an entry of depth 6 and an entry of depth 1, wouldn't you be able to use the depth 6 entry anywhere you could use the depth 1 entry?
Also do you keep track of the depths during a quiescence search, or do you just set them all to -1 when counting the entries for each depth?
@ Thomas
From what I understand, you are only storing the upper 32 bits of the zobrist key in the transposition table. Does this lead to more collisions than if you were to store the full key? Are there any advantages besides reduced memory?
@ H.G.
I've heard this before but I don't really understand why entries with higher depth pollute the table. If you had an entry of depth 6 and an entry of depth 1, wouldn't you be able to use the depth 6 entry anywhere you could use the depth 1 entry?
Also do you keep track of the depths during a quiescence search, or do you just set them all to -1 when counting the entries for each depth?
-
hgm
- Posts: 27796
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Transposition table chaining and replacement strategy
OK, I guess what I said was indeed ambiguous. It is for the size of the tree without hashing. This is why it starts to go up significantly after the loading factor exceeds 3: there are enough transpositions in the tree so that it still fits in its entirety even at that loaading factor.AlvaroBegue wrote:I thought of that possibility, but then it seems like too much of a coincidence that the pairs of points seem to have the exact same horizontal coordinate.
No, it wouldn't, because it is for another position. When I talk about 'replacement' I always refer to (possibly unjustly) what you do when you have a position that was not yet in the table/bucket, so that you have to kick out another position to accomodate it. Having a new search result for a position that was already in the table would just update the entry, and in my mind thus not replace anything. The best algorithm here seems to always overwrite the entry with the new info. Because the old info is apparently useless, or you would not have had to search it again to obtain this new result. So even if the table now contains a d=6 entry, and you have a new d=1 entry, it is better to store the d=1 result. As that could be useful in the future, where the d=6 entry would never be of any use, because it apparently has wrong bounds that made it unsuitable even to satisfy a d=1 search.raccoon wrote:@ H.G.
I've heard this before but I don't really understand why entries with higher depth pollute the table. If you had an entry of depth 6 and an entry of depth 1, wouldn't you be able to use the depth 6 entry anywhere you could use the depth 1 entry?
For actual replacement, when you have the dilemma of keeping a d=1 entry or a d=6 entry of a different position, the argument is this: the d=6 position would save you a lot more work when you encounter it again for a d=6 (or similar) search, much more than the d=1 position. But the tree is traversed in such a way that new d=6 searches are ordered far less frequently than d=1 searches. So on average you will have to hold on to the d=6 entry far longer before you can use it at all, and in the mean time it is occupying a hash-table entry without doing anything at all. An entry that during that period could possibly have contained 1000 d=1 entries each stored for a short time, each providing 1 hit and saving you a little bit of work.
Also note that the use of large-draft entries is often overrated: if you would store no d=6 entries at all, but you could store all d=5, a d=6 search that could have been a hit (because it was done before, but alas, not stored) only takes the work of a d=1 search to search it, as after the first move you will hit upon a d=5 entry you have seen before. If the overloading would be so high that the table could just hold all d=6 nodes of the tree, with no room left for d=5, d=6 searches on positions you have not seen before would become very expensive, because they effectively cannot use the hash table at all. (The d=5 will of course be stored in the always-replace part of the table, but this is bombarded so heavily with d=0 and d=1 entries that it will never survive until the time you order a new d=5 search.) So you gain by reserving some space in the table for d=5, even when this goes at the expense of the number of d=6 you can store.
The draft stored in the hash table should better correspond 1-to-1 to the type of search, so you can easily test if an entry is usable to satisfy a search request. If you would store some QS nodes as d=-3, and others as d=-5, while in fact they were identical searches, you would needlessly prevent that the d=-5 result would be used to satisfy the request for a d=-3 search. (Unless you made the test whether the depth was acceptable extra complex.) Of course you should take into account that levels are really different (e.g. if you search checks at d=-1, but not at d <= -1).Also do you keep track of the depths during a quiescence search, or do you just set them all to -1 when counting the entries for each depth?
-
cetormenter
- Posts: 170
- Joined: Sun Oct 28, 2012 9:46 pm
Re: Transposition table chaining and replacement strategy
Yes it does. However this does not really seem to be a problem. There is a paper written by Robert Hyatt that shows the effects of hash collisions on gameplay located here https://cis.uab.edu/hyatt/collisions.html. It shows that a LOT of hash collisions need to occur in order to significantly effect the engines performance.raccoon wrote: @ Thomas
From what I understand, you are only storing the upper 32 bits of the zobrist key in the transposition table. Does this lead to more collisions than if you were to store the full key? Are there any advantages besides reduced memory?
There aren't any other advantages besides reducing the memory that I know of. However if it does not affect play then it seems to be better to store as many entries as possible without having to worry about an increase in hash collisions.
-
mar
- Posts: 2555
- Joined: Fri Nov 26, 2010 2:00 pm
- Location: Czech Republic
- Full name: Martin Sedlak
Re: Transposition table chaining and replacement strategy
Don't forget that the lower 32 bits are not completely lost as you use them to index TT, so in reality you have more than 32 bits precision, depending on your TT size.raccoon wrote:From what I understand, you are only storing the upper 32 bits of the zobrist key in the transposition table. Does this lead to more collisions than if you were to store the full key? Are there any advantages besides reduced memory?
Even if you had a collision on upper 32 bits (in theory), it's still very unlikely that the lower portion maps to the same bucket.