Who knows maybe two pawns are a lot more worth
 (and yes I am joking)
(and yes I am joking)I guess using different K values for each state might cure their problems.
Moderators: hgm, Rebel, chrisw
Who knows maybe two pawns are a lot more worth
(and yes I am joking)
Ah, ok, now i get your idea. Interesting! Well, indeed, i did not checked that. It might help, but it does not address the quiet criterion which is essential part of a better solution. I, for myself, am pretty satisfied that i already found two major reasons, that lead to somehow normal results.Pio wrote: ↑Wed Jan 20, 2021 1:47 pmWhat I meant using many K values was that you determine as many K values as you have phases so you will have to determine 24 K values each corresponding to one phase. In that way you will have a good mapping between centipawn values and win probabilities for each phase. As it is now you and everyone else makes the assumption that you have the same centipawn to probability mapping for each phase. When you have determined each K value for each phase you will use the K value that corresponds to the position’s phase while minimising the error. So when you sum up the errors over your entire dataset you will use all 24 different K values.Desperado wrote: ↑Wed Jan 20, 2021 1:26 pmHello Pio,Pio wrote: ↑Wed Jan 20, 2021 12:37 pmI understand your point but making huge mispredictions might not be as bad as you think with an engine. What is really important for an alpha beta search is to judge which positions are better than others from a set of positions close to each other. Of course when you search very deep, positions will become more and more different and it will be more important to judge very different positions.hgm wrote: ↑Wed Jan 20, 2021 12:15 pmNot really. The most important by far is that the engine will recognize the positions were one side is leading by a huge amount, and can then correctly identify who is leading. And valuing a Queen like 1.5 Pawn will not do much for recognizing totally won positions.Pio wrote: ↑Wed Jan 20, 2021 12:51 amI am not so sure about that the test set should be as similar as possible to the nodes encountered by its search tree. Unbalanced positions are of course very helpful but positions where one side is leading by a huge amount will not be helpful since it is much more important for the engine to be able to make decisions where the score is even which is the case if you start out a game from the standard opening position.
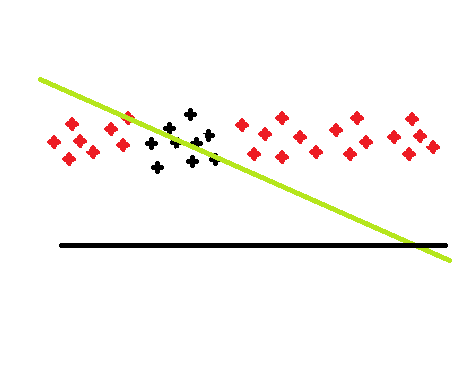
The following image sketches the problem:
The line that best fits the data points in some narrow range (the black points) will adapt its slope to get a marginally better prediction of the accidental vertical scatter. That line is no good for predicting the red points, though. For points sufficiently far from the region on which it was based, it doesn't even get the sign right. So the attempt to get a marginally better discrimination within the black range leads to total disaster in the wings. If you would have taken the red points into account during the fitting, you would have gotten a practical horizontal line, which does a good job everywhere, and is only marginally worse in the black area.
You see that happening here: piece values become non-sensical. This leads to huge mispredictions of heavilay won or lost positions that were left out of the test set, and gives you an engine that strives for forcing losing trades.
I think that if Sven or Desperado would determine different K values for the different phases, they wouldn’t get their strange results.
Minimising the absolute error instead of squared error will make the tuning more robust to labelling errors and will make the evaluation prediction better but might make the search worse, but I really don’t know.
Also putting more weight to the end will automatically make the positions more unbalanced since usually wins comes from unbalanced positions and draws from more balanced positions.
i need to be more detailed at another time. But of course i played around with the loss function and of course i used different K Values.
Some have been reported with some setups and measurements. Conclusion, it keeps to be the data. (It keeps to be like that when i do not restrict the tuner in a way, that it stops early although there might be another mse. Another observation was that the result
became better when using stable(some kind of quiet) positions and full evaluation. It was observable that the pawn value got normal,
and the tuner was able to map the imbalance into other evaluation paramters)
I do not have the numbers at hand for quiet-labeled.epd, but you pointed out for several times that you would use positions more related to an endgame phase. I agree with you that the correlation between the position properties and the result gets stronger. The idea is not bad at all, but i have some
different thoughts on that too. The known quiet-labeled.epd, if i remember correctly, meets the requirements more than the data that was discussed in this thread. I will come back to this topic but in the other thread about training data. Maybe tomorrow.
@HG
I never realized that the people talk about another essential part of the data. The result of a game is strongly influenced by the chess playing
entity. There should be some kind of independency of that fact. We can easily build a database where 3000 elo engines play with handicap against 2000 Elo engines and we would learn that playing with a queen less or a rook less the winning probability will rise
.
Currently i build my own tuning algorithm that will address some intersting topics on that (at least for me).
I report later in the other thread. Maybe tomorrow too.
There might be other reasons why they get strange results:hgm wrote: ↑Wed Jan 20, 2021 12:15 pmNot really. The most important by far is that the engine will recognize the positions were one side is leading by a huge amount, and can then correctly identify who is leading. And valuing a Queen like 1.5 Pawn will not do much for recognizing totally won positions.Pio wrote: ↑Wed Jan 20, 2021 12:51 amI am not so sure about that the test set should be as similar as possible to the nodes encountered by its search tree. Unbalanced positions are of course very helpful but positions where one side is leading by a huge amount will not be helpful since it is much more important for the engine to be able to make decisions where the score is even which is the case if you start out a game from the standard opening position.
The following image sketches the problem:
The line that best fits the data points in some narrow range (the black points) will adapt its slope to get a marginally better prediction of the accidental vertical scatter. That line is no good for predicting the red points, though. For points sufficiently far from the region on which it was based, it doesn't even get the sign right. So the attempt to get a marginally better discrimination within the black range leads to total disaster in the wings. If you would have taken the red points into account during the fitting, you would have gotten a practical horizontal line, which does a good job everywhere, and is only marginally worse in the black area.
You see that happening here: piece values become non-sensical. This leads to huge mispredictions of heavilay won or lost positions that were left out of the test set, and gives you an engine that strives for forcing losing trades.
Have you tried that method of tuning that is using 24 K values?Pio wrote: ↑Wed Jan 20, 2021 1:47 pm What I meant using many K values was that you determine as many K values as you have phases so you will have to determine 24 K values each corresponding to one phase. In that way you will have a good mapping between centipawn values and win probabilities for each phase. As it is now you and everyone else makes the assumption that you have the same centipawn to probability mapping for each phase. When you have determined each K value for each phase you will use the K value that corresponds to the position’s phase while minimising the error. So when you sum up the errors over your entire dataset you will use all 24 different K values.

I don't think this is a good idea at all. Altering the K value is the same as scaling all centi-Pawn eval parameters by the same factor, and it would be more illuminating to do that. And providing 24 independent parameters for that almost certainly will lead to overfitting. It is more likely than not that there is a somewhat continuous dependence of the parameter on the game phase (of which the linear tapering is the most common choice). You could try to improve that to parabolic tapering, but allowing arbitrary wild fluctuations for every piece that gets traded will do mor harm than good (by making each of the parameters less accurately defined).Pio wrote: ↑Wed Jan 20, 2021 1:47 pmWhat I meant using many K values was that you determine as many K values as you have phases so you will have to determine 24 K values each corresponding to one phase. In that way you will have a good mapping between centipawn values and win probabilities for each phase. As it is now you and everyone else makes the assumption that you have the same centipawn to probability mapping for each phase. When you have determined each K value for each phase you will use the K value that corresponds to the position’s phase while minimising the error. So when you sum up the errors over your entire dataset you will use all 24 different K values.
Completely true. Even with a set of test positions that is representative for what an engine encounters in its search, this could be a problem. In fact there is no guarantee that the objectively best evaluation will result in the best play. (Sven already mentioned that.) E.g. a very good evaluation could be able to predict very accurately which side is better in tactically complex situations. But an engine could systematically lose in such situations, because its search makes it tactically inept. Or in a field of equally inept engines, it would score only aboout 50% even from the good ones, because it is just a toss-up which of the players will blunder. So it would then get more Elo by scoring tactically complex positions as 50%, an intentionally wrong prediction for the results of high-level play.Desperado wrote: ↑Tue Jan 19, 2021 10:43 am@HG if there is something wrong in the complete scenario, then it would certainly be the human made assumption that the lowest mse leads to always better gameplay. The tuner or the tuning algorithm only provides this information. It does not tell anybody that the result will perform better in gameplay. You simply do not ask the question to him, you only ask how the best vector would look like for a given data set. That is basically a different question.
A good optimizer should not get stuck in local optima. And note that for terms in which the evaluation is linear (like most terms in hand-crafted evaluations, and certainly the piece values) there shouldn't be any local optima at all. I don't think the sigmoid correction can change that, as it is equivalent to fitting the centi-Pawn scores with a deminishing weight for the scores far from zero.
@Svenhgm wrote: ↑Wed Jan 20, 2021 5:04 pmA good optimizer should not get stuck in local optima. And note that for terms in which the evaluation is linear (like most terms in hand-crafted evaluations, and certainly the piece values) there shouldn't be any local optima at all. I don't think the sigmoid correction can change that, as it is equivalent to fitting the centi-Pawn scores with a deminishing weight for the scores far from zero.
I am not so sure about that. I think the use of different K, absolute error and weigh positions close to en result will contribute to much more reasonable values. I don’t think anything is wrong with their optimisers.hgm wrote: ↑Wed Jan 20, 2021 5:04 pmA good optimizer should not get stuck in local optima. And note that for terms in which the evaluation is linear (like most terms in hand-crafted evaluations, and certainly the piece values) there shouldn't be any local optima at all. I don't think the sigmoid correction can change that, as it is equivalent to fitting the centi-Pawn scores with a deminishing weight for the scores far from zero.