Page 1 of 2
trying to understand mcts
Posted: Wed May 08, 2019 1:10 pm
by flok
Hi,
As the topic says, I'm trying to understand mcts.
I tried implementing it before and that did not work very well (at par with Pos

) so my guess is that I simply have the wrong understanding of how mcts works.
What I did was:
- find which moves there are in the root node
- pick one at random
- play that move by randomly selecting moves from the branch until mate/etc is found
- update statistics:
* count the number of times the moves has been played
* count the number of times the move gave a win, a loss, etc
- then after a couple of times doing so, select the move with the best statistics.
Which part(s) is wrong in this list of steps?
regards
Re: trying to understand mcts
Posted: Wed May 08, 2019 1:47 pm
by smatovic
1) Add UCT
https://www.chessprogramming.org/UCT
Currently you use only Monte Carlo playouts at root node.
2) imo, chess is too tactical for mcts, you have to guide the selection of
nodes somehow. As far as i got it, LC0 uses the policy head to guide the
selection, other approaches use an MC-AB or Best-First-MiniMax in chess.
https://www.chessprogramming.org/MC%CE%B1%CE%B2
https://www.chessprogramming.org/Best-F ... max_Search
--
Srdja
Re: trying to understand mcts
Posted: Wed May 08, 2019 2:01 pm
by flok
Hi,
Thank you for your reply.
Am I right that UCTS is only a matter of selecting which node to explore?
So I apply
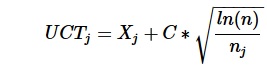
to each root-node and that's it?
Like:
- for each root-move, calculate a score (UCTj)
- find move with highest score and then do a play-out on it
If so: should I then first do a few try-playouts for each root-move to have initial values for that formula?
Re: trying to understand mcts
Posted: Wed May 08, 2019 3:29 pm
by smatovic
flok wrote: ↑Wed May 08, 2019 2:01 pm
Hi,
Thank you for your reply.
Am I right that UCTS is only a matter of selecting which node to explore?
So I apply
to each root-node and that's it?
Like:
- for each root-move, calculate a score (UCTj)
- find move with highest score and then do a play-out on it
If so: should I then first do a few try-playouts for each root-move to have initial values for that formula?
I am not sure what the scientific correct term is for doing monte carlo playouts at root node versus storing the expanded search tree with the according values.
If you want to guide the search via UCT or another method, you will have to store the expanded search tree in memory, not only the root moves. You will need to add an expansion phase to your algorithm, that adds the expanded node to the stored search tree.
I am more into Best First search, but iirc, you can set a parameter in UCT that defines how many playouts have to be played before you expand and add the children of a node to the search tree in memory. For example,
1) select a node (via UCB1 formula ) from search tree in memory until unexpanded node reached
3) if root or playouts > n then expand (add children to tree), goto 1
3) perform a playout, update counters and values of node
4) propagate the results back through the tree in memory
5) goto 1
--
Srdja
Re: trying to understand mcts
Posted: Wed May 08, 2019 4:24 pm
by mjlef
flok wrote: ↑Wed May 08, 2019 1:10 pm
Hi,
As the topic says, I'm trying to understand mcts.
I tried implementing it before and that did not work very well (at par with Pos
) so my guess is that I simply have the wrong understanding of how mcts works.
What I did was:
- find which moves there are in the root node
- pick one at random
- play that move by randomly selecting moves from the branch until mate/etc is found
- update statistics:
* count the number of times the moves has been played
* count the number of times the move gave a win, a loss, etc
- then after a couple of times doing so, select the move with the best statistics.
Which part(s) is wrong in this list of steps?
regards
Srdja's suggestions are great. For MCTS you need to keep a tree in memory. In Komodo MCTS, a node in the tree consists of a visit count, sim of win probabilities, a policy value, a like to the next sibling, and a link to a child node. The key is determining which node to visit. So you start at the root node (the present position) and look at all its children, apply a formula like UCT1 to decide which node to select. The you look at the selected nodes children again using UCT1, and do on until you hit one of these:
a. Checkmate
b. Stalemate
c. 50 move draw
d. rep draw
e. leaf node
A leaf node has no children yet, so if that is selected, you generate its children. Lco/leela/lphaZero all use a NN to generate the win prob at this point, and fill in policy network information in the children. Then you back up the win probability, remembering to flip it as you go up the tree so it is from the point of view of that side. If you use a win prob in the range of 0.0..1.0 you just return 1.0 - winprob as you go up the tree to thr root. You increase the count and add with winprob to the nodes's winprob sum.
Re: trying to understand mcts
Posted: Wed May 08, 2019 4:24 pm
by mjlef
flok wrote: ↑Wed May 08, 2019 1:10 pm
Hi,
As the topic says, I'm trying to understand mcts.
I tried implementing it before and that did not work very well (at par with Pos
) so my guess is that I simply have the wrong understanding of how mcts works.
What I did was:
- find which moves there are in the root node
- pick one at random
- play that move by randomly selecting moves from the branch until mate/etc is found
- update statistics:
* count the number of times the moves has been played
* count the number of times the move gave a win, a loss, etc
- then after a couple of times doing so, select the move with the best statistics.
Which part(s) is wrong in this list of steps?
regards
Srdja's suggestions are great. For MCTS you need to keep a tree in memory. In Komodo MCTS, a node in the tree consists of a visit count, sim of win probabilities, a policy value, a like to the next sibling, and a link to a child node. The key is determining which node to visit. So you start at the root node (the present position) and look at all its children, apply a formula like UCT1 to decide which node to select. The you look at the selected nodes children again using UCT1, and do on until you hit one of these:
a. Checkmate
b. Stalemate
c. 50 move draw
d. rep draw
e. leaf node
A leaf node has no children yet, so if that is selected, you generate its children. Lco/leela/lphaZero all use a NN to generate the win prob at this point, and fill in policy network information in the children. Then you back up the win probability, remembering to flip it as you go up the tree so it is from the point of view of that side. If you use a win prob in the range of 0.0..1.0 you just return 1.0 - winprob as you go up the tree to thr root. You increase the count and add with winprob to the nodes's winprob sum.
Re: trying to understand mcts
Posted: Wed May 08, 2019 6:17 pm
by Michael Sherwin
MCTS will prove not to be optimal. All the mentions of a tree being stored with each node having a pointer to first sibling and a pointer to first child with RL values being stored and updated after every game was done in RomiChess all the way back in 2006. RomiChess remembers every game it plays up to 180 ply. Before every search the subtree if there is one is loaded into the TT. In this way RomiChess does position learning over time. However, the sum is greater than its parts. The values stored into the TT affects the entire search and do not dictate what is played but only sways the search to make the move it makes. So not only does RomiChess essentially learn which moves are better RomiChess learns which moves are better for Romi. For example 1.e4 and 1.d4 are equal. However Romi naturally does better playing 1.d4. Romi after some amount of games learns this and will at some point play only 1. d4. Even after there is no subtree to load all the entries in the TT have been modified by the previous subtrees loaded and the previous searches. Therefore the TT still has information from lines as deep as 180 ply.
The next step that I wanted to take but couldn't because of health problems and advancing age is real time Reinforcement learning. Using a percentage of available time play many fast AB games while storing the games into a tree in memory rather than on the hard drive. Then load those results into the TT. That way the main search using the remaining time has many advantages that it would not normally have like information from much higher in the tree, better move ordering and better LMR data to mention a few. It is therefore my considered opinion that the main search will reach a greater depth even though it was given less time. To understand how many fast games would be required before each main search look at this link.
http://rybkaforum.net/cgi-bin/rybkaforu ... l?tid=3154
So why is MCTS not optimal? Compare the number of random games needed by MCTS compared to the number of games needed by an intelligently directed AB search.
Re: trying to understand mcts
Posted: Wed May 08, 2019 8:15 pm
by mjlef
I do not know if MCTS will surpass alpha-beta. But in K MCTS, the Hash used during search is different from the MCTS Hash which holds the MCTS nodes. Preloading a Hash can be bad unless you have a good replacement scheme to always writ over the hash entries, otherwise the hash gets full of high depth info that is not related to the current search.
Re: trying to understand mcts
Posted: Wed Oct 02, 2019 5:45 pm
by flok
One further question: do I need to recreate the tree for every move? Or can I just cut out the current branch and use that as the new base for the next move?
Re: trying to understand mcts
Posted: Wed Oct 02, 2019 10:25 pm
by smatovic
flok wrote: ↑Wed Oct 02, 2019 5:45 pm
One further question: do I need to recreate the tree for every move? Or can I just cut out the current branch and use that as the new base for the next move?
I tried to reuse the current tree for the next move, but in Zeta v097/v098 I had
to copy the tree back n forth between cpu/gpu, and the memory got quickly
filled, so I kept it as disabled option. But in theory it should give you an
boost.
--
Srdja