I have also problems understanding why computing K has an influence, all I can say it has. If I run the tuner twice with different K it tunes the values differently even if I use the same training set.
If you have a lot of drawn position in your set maybe a good K prevents the tuner from zeroing out all your evaluation terms.
Why computing K that minimizes the sigmoid func. value?...
Moderators: hgm, Rebel, chrisw
-
tpetzke
- Posts: 686
- Joined: Thu Mar 03, 2011 4:57 pm
- Location: Germany
-
Ferdy
- Posts: 4833
- Joined: Sun Aug 10, 2008 3:15 pm
- Location: Philippines
Re: Why computing K that minimizes the sigmoid func. value?.
If you notice at the formula the K defines the sensitiveness of the win probability of the engine output score. This implies that if you like tuning where error is reduced slowly you probably use a higher K.
-
AlvaroBegue
- Posts: 931
- Joined: Tue Mar 09, 2010 3:46 pm
- Location: New York
- Full name: Álvaro Begué (RuyDos)
Re: Why computing K that minimizes the sigmoid func. value?.
All K does is set the evaluation scale. If you measure in pawns, you get some K; if you measure in centipawns, your K will be 100 times smaller. There is nothing mysterious about it. If you are not particularly attached to what a score of +1.0 means, you can fix K=1 (i.e., remove it from the formulas) and nothing will break.
-
tpetzke
- Posts: 686
- Joined: Thu Mar 03, 2011 4:57 pm
- Location: Germany
Re: Why computing K that minimizes the sigmoid func. value?.
Yes that is my theoretical understanding as well but shouldn't the terms than not keep their relationship among each other and the tuned sets should be perform equally well.
In my experiments they don't.
E.g. the value of a queen expressed in pawn units differs a lot depending on what K I use.
In my experiments they don't.
E.g. the value of a queen expressed in pawn units differs a lot depending on what K I use.
-
AlvaroBegue
- Posts: 931
- Joined: Tue Mar 09, 2010 3:46 pm
- Location: New York
- Full name: Álvaro Begué (RuyDos)
Re: Why computing K that minimizes the sigmoid func. value?.
What I am saying is simple arithmetic, so I smell a bug.tpetzke wrote:Yes that is my theoretical understanding as well but shouldn't the terms than not keep their relationship among each other and the tuned sets should be perform equally well.
In my experiments they don't.
E.g. the value of a queen expressed in pawn units differs a lot depending on what K I use.
-
Robert Pope
- Posts: 558
- Joined: Sat Mar 25, 2006 8:27 pm
Re: Why computing K that minimizes the sigmoid func. value?.
I think of K as a way to try to get the sigmoid function to fit as well as possible with the way your evaluation function maps to winning chances. As your engine's score goes from 100 to 200 to 300, your winning chances are increasing, but how quickly? If you choose a sigmoid that has a bad relationship with what your raw score actually means, then the fit will be bad and you will have biased residual errors. So then the optimization process is spending its time trying to get rid of this bias instead of actually improving the predictiveness.Desperado wrote:Good morning,
thanks for your replies, but i still don't understand it.
I think it is absolutely clear to me that the absolute score of the mapped cp value does change with different K. But is it important ?
The mapped value of 600cp will always be greater than for 100cp as long both are computed with the same K.
Because of that, the tuner will always make the same decisions and it does not matter which K you use, it only matters that K needs to be constant.
What do i overlook in this picture ?
The optimization process is like trying to pick a regression line that fits your data. Not picking a good K is like insisting that the line has to have a y-intercept of 5, when the observed data mostly goes through the origin. No matter how you tweak the slope K in y=Kx+5, it's never going to be a good fit for y=3x.
-
petero2
- Posts: 684
- Joined: Mon Apr 19, 2010 7:07 pm
- Location: Sweden
- Full name: Peter Osterlund
Re: Why computing K that minimizes the sigmoid func. value?.
The idea is to disturb the search as little as possible.Desperado wrote:i just read the chessprogramming article about Texels tuning algorithm and found the following part which i do not understand.Can someone explain why this step will help or needs to be done?Code: Select all
Sigmoid(s)=1/(1+10^(-K*s/400)) K is a scaling constant. Compute the K that minimizes E. K is never changed again by the algorithm.
A typical chess program has several search related parameters that can not be tuned by the texel method. This includes for example aspiration window sizes, futility margins and razor margins.
From the point of view of the evaluation function the K value does not matter. It just works as a scale factor for the whole evaluation function, basically determining if the base value of a pawn is 100, 200, or something else.
However, changing the scale of the evaluation function would make search related parameters no longer suitable for the new evaluation function. In order to reduce this effect, the algorithm starts by computing the K value that minimizes E when all evaluation parameters are kept constant.
-
petero2
- Posts: 684
- Joined: Mon Apr 19, 2010 7:07 pm
- Location: Sweden
- Full name: Peter Osterlund
Re: Why computing K that minimizes the sigmoid func. value?.
I can think of a few reasons why this would happen:tpetzke wrote:I have also problems understanding why computing K has an influence, all I can say it has. If I run the tuner twice with different K it tunes the values differently even if I use the same training set.
1. If your evaluation function does not contain enough parameters to make it possible to re-scale the whole evaluation function, different K values can lead to different optimal E values. As a simple but non-realistic example, assume the evaluation function has the form:
Code: Select all
q = w1 * feature1 + feature2Code: Select all
q = w1 * feature1 + w2 * feature22. Even if the evaluation function has enough parameters to be able to exactly represent a scale factor change, it is possible that the used optimization method will find a different local minimum when using a different K value.
3. Typical chess programs use integer arithmetic when computing the evaluation score. Even if the evaluation function can exactly represent a scale factor change, and the optimization method would find the same local minimum for arbitrary K values when real number arithmetic is used, there is no guarantee that this would still be the case when integer rounding effects are present.
-
Ferdy
- Posts: 4833
- Joined: Sun Aug 10, 2008 3:15 pm
- Location: Philippines
Re: Why computing K that minimizes the sigmoid func. value?.
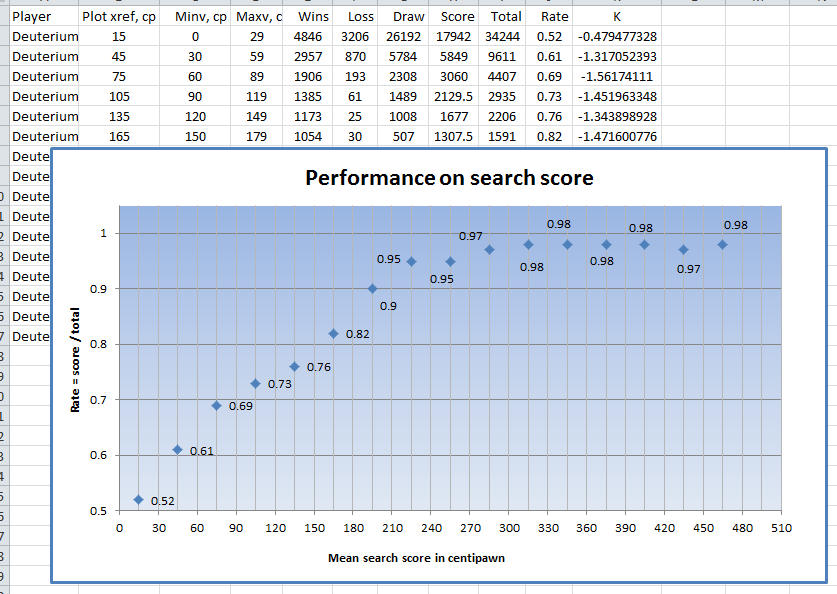
Get games of Deuterium from Frank's page, extract positions played as white and get stats based on move search score range [minv, maxv], to get the perf.
Only those positions with material unit value of 40 or more for both sides where Q=10, R=5, minors = 3, pawn excluded are considered. Here I can get an idea of what initial K I am going to use.
There are some opponents here that are significantly stronger, perhaps the perf is higher at given score range when opponents are close in strength.
Also in tuning it uses qsearch() only whereas in the plot it is from search score from a game of TC 40/10.
Only those positions with material unit value of 40 or more for both sides where Q=10, R=5, minors = 3, pawn excluded are considered. Here I can get an idea of what initial K I am going to use.
There are some opponents here that are significantly stronger, perhaps the perf is higher at given score range when opponents are close in strength.
Also in tuning it uses qsearch() only whereas in the plot it is from search score from a game of TC 40/10.
-
brtzsnr
- Posts: 433
- Joined: Fri Jan 16, 2015 4:02 pm
Re: Why computing K that minimizes the sigmoid func. value?.
Agreed. K is just a scaling parameter. Finding K that minimizes the error just gives you the K for current tuned values.AlvaroBegue wrote:All K does is set the evaluation scale. If you measure in pawns, you get some K; if you measure in centipawns, your K will be 100 times smaller. There is nothing mysterious about it. If you are not particularly attached to what a score of +1.0 means, you can fix K=1 (i.e., remove it from the formulas) and nothing will break.
However, from my experience with Texel's Tuning Method it's better to tune all weights at once because some of them might be correlated. Then, if you tune all of them, scaling matters only to get one pawn ~100 points.
zurichess - http://www.zurichess.xyz