
Did you look at the link I send ? I will repost it here for people who are too lazy to click on it:bob wrote:Stick to topics you understand.lucasart wrote:Nobody cares about NPS scaling. It's the wrong measure. Searching more nodes is not a goal in itself. Winning more games is. It's ELO we care about. Here's the evidence that shows that there's a big problem with Crafty's scaling from 8 to 16 cores:bob wrote:It doesn't on my machine. It depends on the box. The PC is not exactly the perfect platform. 16 cores typically has two chips although it could be a single now. 16 cores on a single chip, with a single path to memory has a problem.lucasart wrote:If you've understood all this since.the 80's, how come Crafty scales so badly from 8 to 16 cores ?bob wrote: I didn't understand it because spLevel was not in the Stockfish6 code I looked at. That change is not going to be worth 50 Elo or so however. But I will let YOU figure out why. And yes, if you look at my old DTS paper this kind of thing was factored in. There's very little new stuff in normal PVS/YBW type parallel searching.
Additionally, I chose to write Crafty in a simpler way that the DTS algorithm used in Cray Blitz. I may well go back and rewrite that one day, because it is significantly better. It just hasn't been a high priority. But the issues for SMP scaling are not new. SMP search has been around for almost 40 years now... Alpha/Beta hasn't changed.
On the 12-core box I use occasionally (dual 6 core chips) the scaling is almost perfect. 5.5M NPS on one core, 60M NPS on 12 cores. You do have to know what you are doing when testing, and make certain turbo is disabled, or the answers are useless. Most miss that.
http://www.talkchess.com/forum/viewtopi ... ght=crafty
If your NPS scaling is bad, EVERYTHING parallel is bad. If your NPS scaling is good, then you have a chance to do decently on the usual SMP speedup measurements. But if your NPS is 1/2 of what it should be, your speedup is guaranteed to be 1/2 of what it could be as well.
Here's one 16 core run I made about a month ago that shows that for this specific 2x8core box, scaling was within reason and can be improved a bit:Those are not that bad. Different machines behave differently and require some tuning. If that represents a "big problem" I will keep it. Every time I move to something new it takes some tweaking... ho hum.Code: Select all
1-core = nps= 6.1M --- 4-cores = nps=23.7M 4.0x 8-cores = nps=45.0M 7.4x 16-cores = nps=86.2M 14.1x
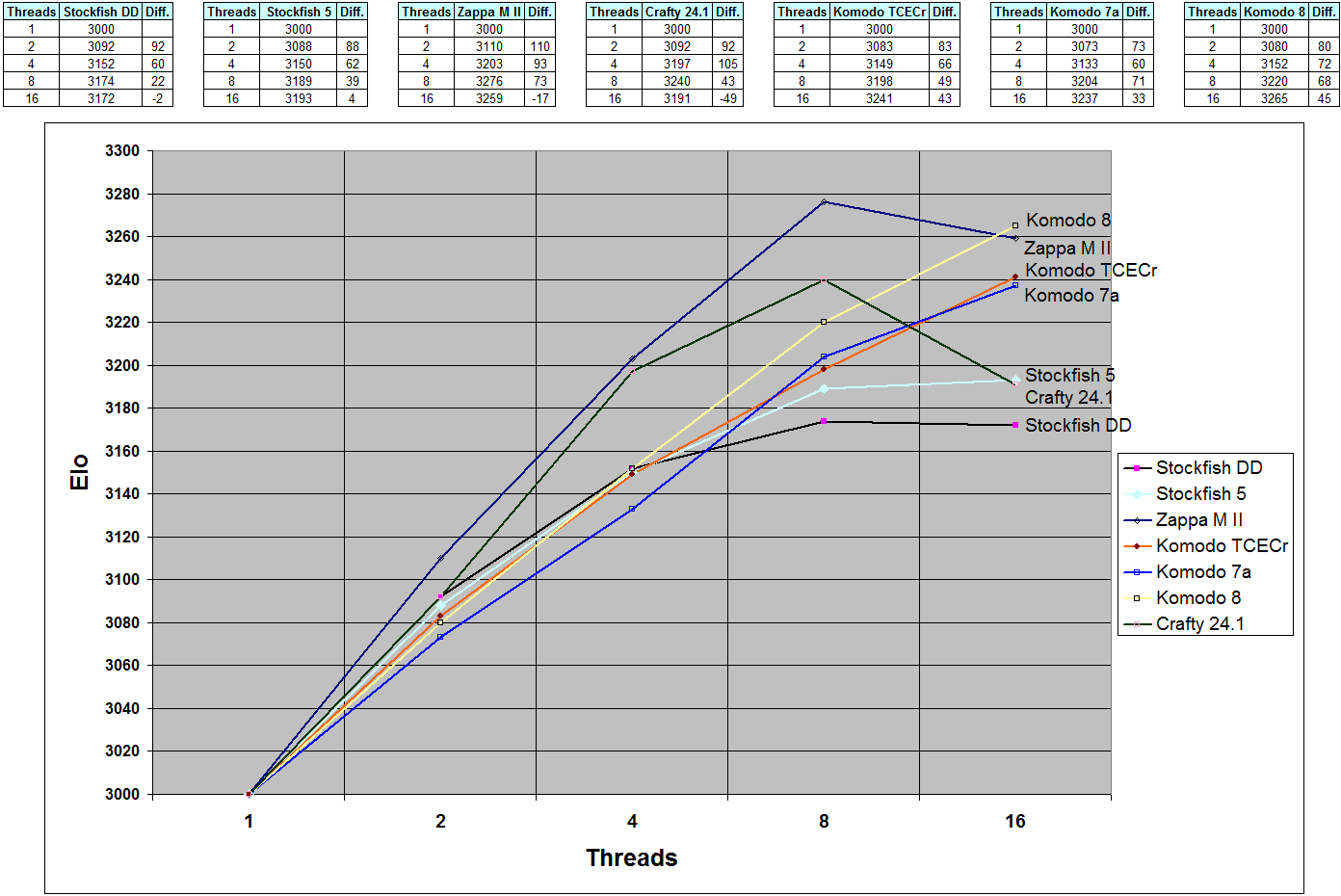
Going from 8 to 16 cores, Crafty loses 50 elo. But it almost doubles NPS, so I guess it's fine by your standard
And you keep trying to lecture everyone about Cray Blitz or Crafty way of doing SMP, as if it were the reference of correctness ? A few years ago, you lectured Marco when he came up with the "Active Reparenting" patch. Later, Joona retried it (thanks to fishtest we could test with many cores), and it was a huge success. Now Joona improved it dramatically, gaining almost 50 elo on 16 cores, and you try to lecture him that his reasoning is flawed and his idea cannot work. Nobody in SF team cares about your opinion (or anyone's opinion). We only care about reality, which means ELO. And when reality disgrees with the great Profesor Hyatt, it means that the great Professor Hyatt is wrong. PERIOD.
Even Cheng's lazy SMP scales better than Crafty on 16 cores (using the correct measure which is ELO). Doesn't that tell you that your DTS algorithm (or the way you implemented it) has some issues ? Or do you prefer to tuck your head in the sand and keep believing that the world is flat ?
Do you ever question yourself ? Or do you prefer to question reality (=ELO) when it doesn't agree with you ?