AlvaroBegue wrote:I thought of that possibility, but then it seems like too much of a coincidence that the pairs of points seem to have the exact same horizontal coordinate.
OK, I guess what I said was indeed ambiguous. It is for the size of the tree
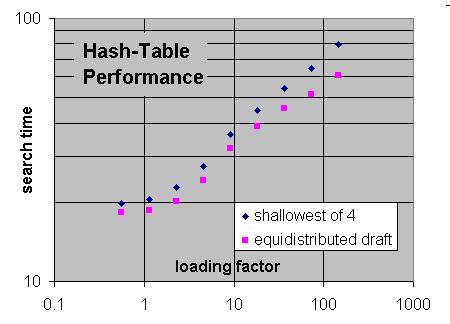
without hashing. This is why it starts to go up significantly after the loading factor exceeds 3: there are enough transpositions in the tree so that it still fits in its entirety even at that loaading factor.
raccoon wrote:@ H.G.
I've heard this before but I don't really understand why entries with higher depth pollute the table. If you had an entry of depth 6 and an entry of depth 1, wouldn't you be able to use the depth 6 entry anywhere you could use the depth 1 entry?
No, it wouldn't, because it is
for another position. When I talk about 'replacement' I always refer to (possibly unjustly) what you do when you have a position that was not yet in the table/bucket, so that you have to kick out another position to accomodate it. Having a new search result for a position that was already in the table would just
update the entry, and in my mind thus not replace anything. The best algorithm here seems to always overwrite the entry with the new info. Because the old info is apparently useless, or you would not have had to search it again to obtain this new result. So even if the table now contains a d=6 entry, and you have a new d=1 entry, it is better to store the d=1 result. As that could be useful in the future, where the d=6 entry would never be of any use, because it apparently has wrong bounds that made it unsuitable even to satisfy a d=1 search.
For actual replacement, when you have the dilemma of keeping a d=1 entry or a d=6 entry of a different position, the argument is this: the d=6 position would save you a lot more work
when you encounter it again for a d=6 (or similar) search, much more than the d=1 position. But the tree is traversed in such a way that new d=6 searches are ordered far less frequently than d=1 searches. So on average you will have to hold on to the d=6 entry far longer before you can use it at all, and in the mean time it is occupying a hash-table entry without doing anything at all. An entry that during that period could possibly have contained 1000 d=1 entries each stored for a short time, each providing 1 hit and saving you a little bit of work.
Also note that the use of large-draft entries is often overrated: if you would store no d=6 entries at all, but you could store all d=5, a d=6 search that could have been a hit (because it was done before, but alas, not stored) only takes the work of a d=1 search to search it, as after the first move you will hit upon a d=5 entry you have seen before. If the overloading would be so high that the table could just hold all d=6 nodes of the tree, with no room left for d=5, d=6 searches on positions you have not seen before would become very expensive, because they effectively cannot use the hash table at all. (The d=5 will of course be stored in the always-replace part of the table, but this is bombarded so heavily with d=0 and d=1 entries that it will never survive until the time you order a new d=5 search.) So you gain by reserving some space in the table for d=5, even when this goes at the expense of the number of d=6 you can store.
Also do you keep track of the depths during a quiescence search, or do you just set them all to -1 when counting the entries for each depth?
The draft stored in the hash table should better correspond 1-to-1 to the type of search, so you can easily test if an entry is usable to satisfy a search request. If you would store some QS nodes as d=-3, and others as d=-5, while in fact they were identical searches, you would needlessly prevent that the d=-5 result would be used to satisfy the request for a d=-3 search. (Unless you made the test whether the depth was acceptable extra complex.) Of course you should take into account that levels are really different (e.g. if you search checks at d=-1, but not at d <= -1).