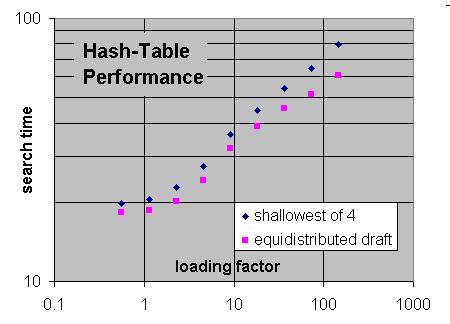
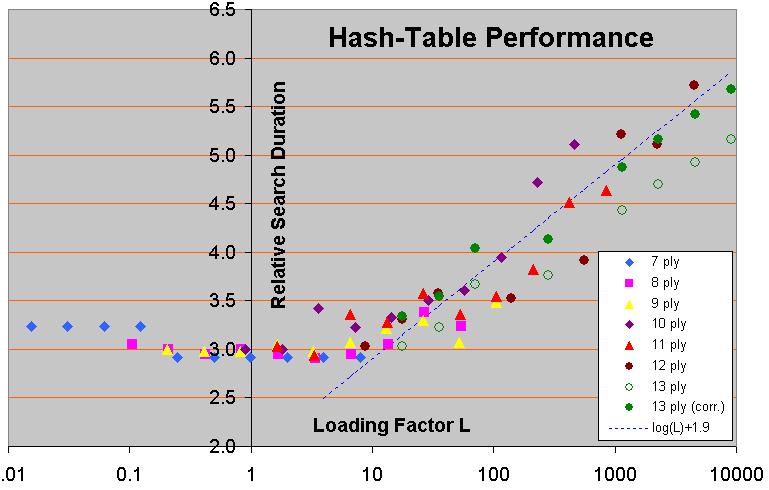
My own program also responds much quicker the second time, due to information in the hash tables, but not nearly so much as Rybka.
I have experimented so far with 3 basic replacement schemes:
- a very basic scheme that does not overwrite a deeper entry, otherwise it always overwrites. Only 1 probe.
- A scheme that segments the table into sets of 4 records and the program chooses the "best" entry among the 4. When writing it's possible that no entries are appropriate because it will not overwrite an entry of greater depth.
- The standard 2 level table, depth based for one, always overwrite for the other.
I am trying to collect information on what variations of schemes people have tried to guide my own experiments. This information is not in one place, but it's scattered throughout various posts and pretty incomplete. They rarely provide the gory details.
What I've also noticed is that in fixed depth 9 ply games some schemes appear to play "stronger" by a few ELO than others. I cannot be completely sure of this since the difference is only about 15 ELO and I have played less than 10,000 games (it could be statistical noise) but it's clear the searches vary signficantly enough that the games with the same openings are not duplicating. With LMR you would clearly expect that, so no surprise. I would also expect that the better implementation could have a slight impact on strength, at least when combined with LMR.
Here is the exact thing I'm doing with method 3 (the standard 2 level table) keeping in mind that AGE always trumps anything else, so an entry is viewed as empty if it was produced by a previous search:
if the depth based entry has a greater depth, use the entry from the always replace table. Whichever is used, gets overwritten regardless of the key. I have not experimented with whether to overwrite the depth entry if the KEY matches (even if the depth in the table is higher.)
Some other details I have heard that people use:
1. I think Bob Hyatt does not overwrite the depth based table when age is CLOSE to the current age.
2. Rybka (it is claimed) does not store scores that are extremely high or low but I'm not sure of the details. It is miserably slower for me when I do this so I cannot imagine what Rybka is doing.
3. Give each hash table entry 2 sets of values, depth based and always overwrite. This is a little different from method 3, the standard 2 level table because the key can be shared.
4. Various probing schemes, such as set associative (which is what seems to work best for me) and linear hashing to find an entry.
5. Depth based 2 level table is a different size (2X ?)
I have found in the simple implementation that you should always overwrite an entry with the same key. I have not tried to experiment with this too much.
There are a zillion details of course on how this might be done and I fear I missing some big point.