Page 1 of 1
CPU Vector Unit, the new jam for NNs...
Posted: Wed Nov 18, 2020 9:23 am
by smatovic
Heyho, you are already aware of it, NNUE uses the CPU Vector Unit to boost NNs,
so here a lill biased overview of SIMD units in CPUs...
- the term SIMD and Vector Unit can be used analogous
- a SIMD unit executes n times the same instruction/operation on different data
- SIMD units differ in bit width, for example from 64 to 512 bits
- SIMD units differ in support for different instructions/operations
- SIMD units differ in support for different data types
- SIMD units may run with a lower frequency than the main CPU ALUs
- SIMD units increase power usage and TDP of the CPU under load
Simplified, older CPUs have 128 bit SSE units, newer ones 256 bit AVX2, ARM
mobile processors for example 128 bit NEO.
A 128 bit SSE unit can perform for example 4x 32 bit FP32 operations at once, a
256 bit AVX2 unit can perform 16x 16 bit INT16 operations at once. The broader
the bit width and the smaller the data-types, the more operations you can run
at once, the more throughput you get. NNs can run for example with FP16,
floating point 16 bit, or also with INT8, integer 8 bit, inference.
Currently Intel's AVX-512 clocks significantly down under load, so there is no
speed gain by broader bit-width compared to AVX2, may change in future. Also
there is an trend to multiple Vector Units per CPU core underway.
--
Srdja
Re: CPU Vector Unit, the new jam for NNs...
Posted: Wed Nov 18, 2020 1:05 pm
by Gerd Isenberg
Yep, SSE2 introduced integer vectors of 16 bytes, eight 16-bit words, four 32-bit double words or two 64bit quad words. Still proud of the
64bit x 64byte dot-product:
Code: Select all
/* for average weights < 64 */
int dotProduct64(U64 bb, BYTE weightsRot90[] /* XMM_ALIGN */)
{
static const U64 CACHE_ALIGN masks[8] = {
C64(0x0101010101010101), C64(0x0202020202020202),
C64(0x0404040404040404), C64(0x0808080808080808),
C64(0x1010101010101010), C64(0x2020202020202020),
C64(0x4040404040404040), C64(0x8080808080808080),
};
__m128i x0, x1, x2, x3, zr; U32 cnt;
__m128i * pM = (__m128i*) masks;
__m128i * pW = (__m128i*) weightsRot90;
x0 = _mm_cvtsi64x_si128 (bb);
x0 = _mm_unpacklo_epi64 (x0, x0);
zr = _mm_setzero_si128 ();
x3 = _mm_andnot_si128 (x0, pM[3]);
x2 = _mm_andnot_si128 (x0, pM[2]);
x1 = _mm_andnot_si128 (x0, pM[1]);
x0 = _mm_andnot_si128 (x0, pM[0]);
x3 = _mm_cmpeq_epi8 (x3, zr);
x2 = _mm_cmpeq_epi8 (x2, zr);
x1 = _mm_cmpeq_epi8 (x1, zr);
x0 = _mm_cmpeq_epi8 (x0, zr);
// multiply by "and" with -1 or 0
x3 = _mm_and_si128 (x3, pW[3]);
x2 = _mm_and_si128 (x2, pW[2]);
x1 = _mm_and_si128 (x1, pW[1]);
x0 = _mm_and_si128 (x0, pW[0]);
// add all bytes (with saturation)
x3 = _mm_adds_epu8 (x3, x2);
x0 = _mm_adds_epu8 (x0, x1);
x0 = _mm_adds_epu8 (x0, x3);
x0 = _mm_sad_epu8 (x0, zr);
return _mm_cvtsi128_si32(x0)
+ _mm_extract_epi16(x0, 4);
}
Re: CPU Vector Unit, the new jam for NNs...
Posted: Wed Nov 18, 2020 2:40 pm
by Jhoravi
What do the latest ARM CPU with AI acceleration offer in comparison?
Re: CPU Vector Unit, the new jam for NNs...
Posted: Wed Nov 18, 2020 3:34 pm
by Gerd Isenberg
Jhoravi wrote: ↑Wed Nov 18, 2020 2:40 pm
What do the latest ARM CPU with AI acceleration offer in comparison?
ARM has Advanced SIMD aka
NEON, a combined 64- and 128-bit SIMD instruction set.
Re: CPU Vector Unit, the new jam for NNs...
Posted: Wed Nov 18, 2020 5:14 pm
by Jhoravi
Gerd Isenberg wrote: ↑Wed Nov 18, 2020 3:34 pm
Jhoravi wrote: ↑Wed Nov 18, 2020 2:40 pm
What do the latest ARM CPU with AI acceleration offer in comparison?
ARM has Advanced SIMD aka
NEON, a combined 64- and 128-bit SIMD instruction set.
But NEON is old. I heard that AI acceleration in recent ARM flagships especially in Huawei's Kirin are being showcased with far leading benchmarks in AI tasks. Does in help in NNUE?
Re: CPU Vector Unit, the new jam for NNs...
Posted: Wed Nov 18, 2020 5:58 pm
by Gerd Isenberg
Jhoravi wrote: ↑Wed Nov 18, 2020 5:14 pm
Gerd Isenberg wrote: ↑Wed Nov 18, 2020 3:34 pm
Jhoravi wrote: ↑Wed Nov 18, 2020 2:40 pm
What do the latest ARM CPU with AI acceleration offer in comparison?
ARM has Advanced SIMD aka
NEON, a combined 64- and 128-bit SIMD instruction set.
But NEON is old. I heard that AI acceleration in recent ARM flagships especially in Huawei's Kirin are being showcased with far leading benchmarks in AI tasks. Does in help in NNUE?
That seems to be
Helium. Surely it will be faster for NNUE than ARM general purpose - whether it is better than NEON - per Watt, yes.
Re: CPU Vector Unit, the new jam for NNs...
Posted: Thu Nov 19, 2020 4:51 am
by Jhoravi
Gerd Isenberg wrote: ↑Wed Nov 18, 2020 5:58 pm
That seems to be
Helium. Surely it will be faster for NNUE than ARM general purpose - whether it is better than NEON - per Watt, yes.
For instance Huawei was talking about Dual Neural Processing in their ARM CPU while Qualcomm talks about Hexagon NN. I believe it's more than just Helium.
Re: CPU Vector Unit, the new jam for NNs...
Posted: Thu Nov 19, 2020 6:01 am
by smatovic
Jhoravi wrote: ↑Thu Nov 19, 2020 4:51 am
Gerd Isenberg wrote: ↑Wed Nov 18, 2020 5:58 pm
That seems to be
Helium. Surely it will be faster for NNUE than ARM general purpose - whether it is better than NEON - per Watt, yes.
For instance Huawei was talking about Dual Neural Processing in their ARM CPU while Qualcomm talks about Hexagon NN. I believe it's more than just Helium.
There are several neural network engines/accelerators out there from different vendors, as far as I got it these are basically matrix-multiply-accumulate units, like a TPU - Tensor Processing Unit, Intel plans to put such a thing on its x86 Xeon line in 2021, so there seems to be a trend for TPU on CPU. Offers for sure new possibilities in NN programming, if there are open standards (APIs/compilers) for programmers and if this competes vs. broader/multiple Vector Units remains open IMO.
--
Srdja
Re: CPU Vector Unit, the new jam for NNs...
Posted: Thu Nov 19, 2020 11:10 pm
by mmt
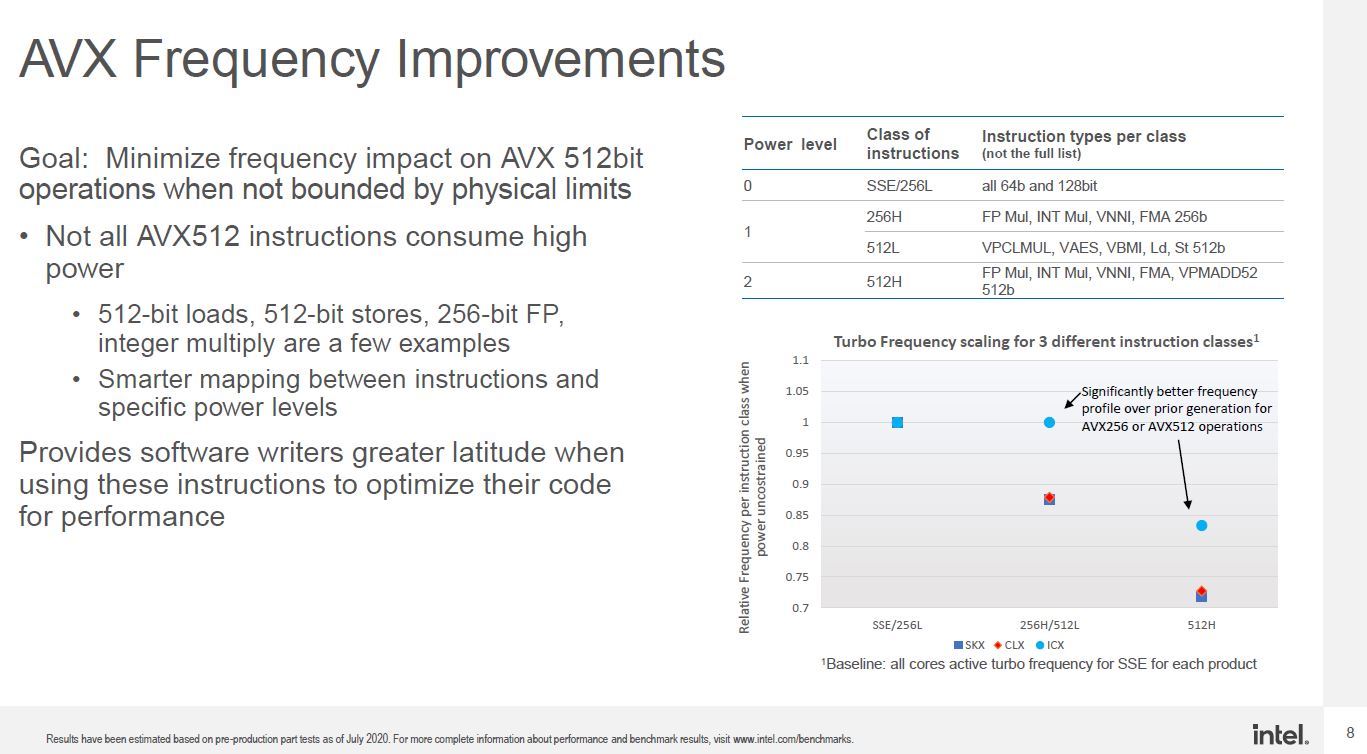
smatovic wrote: ↑Wed Nov 18, 2020 9:23 am
Currently Intel's AVX-512 clocks significantly down under load, so there is no
speed gain by broader bit-width compared to AVX2, may change in future. Also
there is an trend to multiple Vector Units per CPU core underway.
Intel's upcoming Ice Lake processors are supposed to do this:
 https://www.servethehome.com/intel-ice- ... m-release/
https://www.servethehome.com/intel-ice- ... m-release/
But I'd still rather take twice as many cores with AVX2 from AMD.