IIRC AlphaZero used Dirichlet noise. Do you know why? The cumulative distribution function looks like that (2 dimensional vector of 0.3, 1 dimensional simplex):jkiliani wrote:Lc0 currently has the problem that randomness in match games is provided only by the relatively small perturbations of the root node scores from Dirichlet noise. This can only shift the PV when two moves are similar already in evaluated quality, and leads to sometimes long opening lines played in almost every game within a particular match.Laskos wrote:I use a varied, but solid short opening suite 3moves_GM. They seem to overfit on certain openings, finding local optima, playing most of the games on them, and training less on many other viable openings. I don't know whether they will soon find it problematic what to promote or not. 300,000 games with +0 Elo against a standard engine is not that good.
I wrote a solution to this issue in https://github.com/glinscott/leela-chess/pull/267. Once this is used in match games, openings will be much more varied again. It will probably happen in a couple of days, after the next forced version upgrade.

So, it seems to favor very small deviation and very large deviations. I don't know why say very much pruned out branches at the root should be taken so seriously into account.
Isn't this simple, 1/sqrt(x) distribution, more sensible:

Anyway, I will have to inform myself better, I don't understand the topic. And anyway, the noise in opening should be much larger. Standard opening position is just one, all other parts of the games have very high diversity, so for the beginning of the openings, a very different kind of noise should be used.
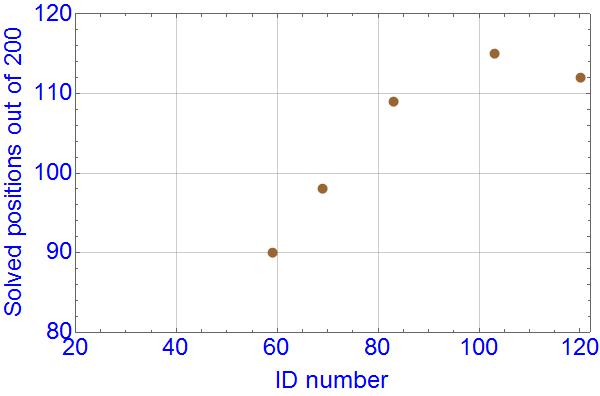
And to the progress:
Within error margins, no significant progress was made in my flawed testing from ID101 to ID113, almost 500,000 games, which is worrying. Their self-games ratings show 110 Elo points progress, while my results in 500 games against a standard engine Predateur are:
Code: Select all
LCZero CPU ID83 4 threads 153.0/500 134-328-38
LCZero CPU ID101 4 threads 202.0/500 181-277-42
LCZero CPU ID113 4 threads 206.5/500 183-270-47