hgm wrote:This theorem uses 'full' in a meaning that has no practical relevance. I don't care if if there still is a single empty entry in a table of a million, and that it would take a million more stores to get a hit on that entry that fills it. From a performance point of view a table that is still 10% empty is practically indistinguishable from a full table. The performance starts to fall when you start to overwirte entries, and this in fact happens significantly before the number of stores equals the table size. ...
I disagree. The purpose of a hash table is to get hits. One factor controlling the number of hits is the percentage of entries in the table that are occupied. If the TT is empty then it's completely worthless.
So, I guess you need to define the word “performance” explicitly as your current usage seems counter-intuitive and vague. I think a TT is performing at it's best when it's completely full since this is when it has the highest probability of producing a hit when all other factors are held constant.
This graph of yours:
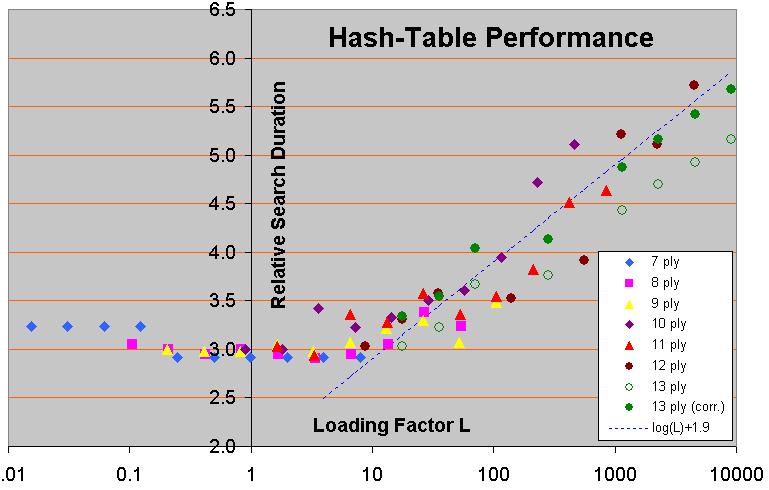 Effect of hash-table size on search time
Effect of hash-table size on search time
Seems to contradict your statement that “
performance starts to fall when you start to overwirte entries". It's not clear how “loading factor” is defined as used in the graph but, assuming it is related to the number of unique stores in to a table of k entries in a linear way, (e.g. a loading factor of 10 represents 10 * k unique stores into a hash table of k entries), then it looks to me like the performance stays about the same over a wide range of “loading factors”. i.e. from ~ 0.5 to ~5. This contradicts your 1/e example.
hgm wrote:...In an always-replace table of size k after k stores 1/e of the table would still be empty. But only by virtue that 1/e of the stored entries have already been overwritten, which will cause a very significant performance drop. ...
A “significant performance drop” as compared to what? An infinite size table?
I doubt this is true and your graph certainly doesn't support this conclusion. In order for there to be any degradation in performance a location has to be referenced at least 3 times. Once to place an entry in it, once to overwrite it, and once to reference the original data and this has to happen in that order. If the data in the cell is referenced and produces a hit before its over-written no performance is lost. At least not until another (fourth) reference to that location is made.
hgm wrote:... I vaguely recall that for perft(6) the number of unique positions is already an order of magnitude smaller than the number of nodes.
I think I'll stand by my previous assertion that the number of entries in the hash table is the controlling factor here and not the number of transpositions, since if the transpositions were the cause of this effect the cache hit rate would be VERY high. Besides, what engine uses a full width search without Alpha-Beta which is what this statement seems to imply.
Regards,
Zen
Only 2 defining forces have ever offered to die for you.....Jesus Christ and the American Soldier. One died for your soul, the other for your freedom.
