The rule of thumb is that 'recent' is more important than any other property. Depth is a very misleading property. It correlates with how much work you have to do when you would have to redo the search from scratch, with an empty hash table. But the hash table isn't empty, and other parts of the tree sprouting from the node you consider overwriting have once been in there too. If it is a d=20 node, but all its d=19 daughters are still in the table, losing the entry only takes you a 1-ply search to recover the d=20 result.
So you must judge the value of the entry based on the statistical expectation of how much work it takes to reconstruct it. Which depends on which fraction of the nodes in its sub-tree is still in the table.
You should also consider how long you have to keep the entry before you get a hit on it. Entries with very large draft will be close to the root, and most of the tree will not be able to get hits on it at all, because of an irreversible move between them and the root incompatible with the position. So hits on it come from other nodes close to the root. And the moves near the root change only very slowly. So the larger the draft, the lower the frequency of hits on them. By using that same table slot to store thousands of short-living positions with a much lower draft that cause 10,000 hits that only save you 1/1000th of the work of the high-draft entry, you still save more work. This makes recent entries so important: they have a high hit rate as you are apparently working so near to it in the tree that it is easy to transpose to them.
Transposition Age Tutorial
Moderators: hgm, Rebel, chrisw
-
hgm

- Posts: 27794
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
-
D Sceviour
- Posts: 570
- Joined: Mon Jul 20, 2015 5:06 pm
Re: Transposition Age Tutorial
That is what was intended by suggesting to overwrite the entry that has the largest variance from the current alpha/beta bounds. An entry that has a value very close to current bounds might be expected to be more recent, or more useful as a first try best move. Of course this is still conjecture, as it needs a practical test.
Bob Hyatt has also mentioned that this stuff has already been tested to death.
Bob Hyatt has also mentioned that this stuff has already been tested to death.
-
bob
- Posts: 20943
- Joined: Mon Feb 27, 2006 7:30 pm
- Location: Birmingham, AL
Re: Transposition Age Tutorial
Here's a couple I had a note for:D Sceviour wrote:That is what was intended by suggesting to overwrite the entry that has the largest variance from the current alpha/beta bounds. An entry that has a value very close to current bounds might be expected to be more recent, or more useful as a first try best move. Of course this is still conjecture, as it needs a practical test.
Bob Hyatt has also mentioned that this stuff has already been tested to death.
Information in Transposition Tables
D M Breuker J W H M Uiterwijk and H J van den Herik
Replacement Schemes for Transposition Tables
same group of authors more or less.
-
hgm
- Posts: 27794
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Transposition Age Tutorial
What tested best for me was equi-distributed-draft replacement: replacing the entry with the draft that already occurs the most in the transposition table, irrespective of age. You just keep an array of counters, one for every draft, and you look up in the array how many of each draft in the bucket are already in the the table, and pick the entry that occurs the most. I.e. pick based on max(occurrence[depth]) rather than min(depth). And then of course update the counters when you replace.D Sceviour wrote:That is what was intended by suggesting to overwrite the entry that has the largest variance from the current alpha/beta bounds. An entry that has a value very close to current bounds might be expected to be more recent, or more useful as a first try best move. Of course this is still conjecture, as it needs a practical test.
Bob Hyatt has also mentioned that this stuff has already been tested to death.
A poor-man's approximation of this is 'under-cut replacement': Map each position to a 'primary entry' in the bucket. Replace that entry with a probability the inverse of the branching factor if the draft is exactly one higher than that of the position you need to store ('under-cut). Otherwise replace the entry in the bucket with the lowest draft, if that draft is equal or smaller to that of the entry to store. If even that is higher, store in the 'always-replace' entry in the bucket. This drives over-represented drafts out of the table, as the more there are, the more often they will be undercut.
-
jwes
- Posts: 778
- Joined: Sat Jul 01, 2006 7:11 am
Re: Transposition Age Tutorial
https://www.researchgate.net/publicatio ... ion_Tablesbob wrote:Here's a couple I had a note for:D Sceviour wrote:That is what was intended by suggesting to overwrite the entry that has the largest variance from the current alpha/beta bounds. An entry that has a value very close to current bounds might be expected to be more recent, or more useful as a first try best move. Of course this is still conjecture, as it needs a practical test.
Bob Hyatt has also mentioned that this stuff has already been tested to death.
Information in Transposition Tables
D M Breuker J W H M Uiterwijk and H J van den Herik
Replacement Schemes for Transposition Tables
same group of authors more or less.
https://www.researchgate.net/publicatio ... ion_Tables
-
hgm
- Posts: 27794
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Transposition Age Tutorial
But note that these papers only describe very basic replacement schemes, hardly in use anymore by almost any serious program of today. Fairy-Max uses 'always replace', which in the paper is called 'New', because of its minimalistic approach. But the most-advanced 'two-level' schemes they use (of which 'TwoDeep' apparently tests as best) have been superseded by implementations that not decide beforehand which table entry is to hold the Deep and which the New, but makes this choice dynamically by replacing the entry with the smallest draft ('shallowest-of-two'). And almost everyone uses 'shallowest-of-four' nowadays.
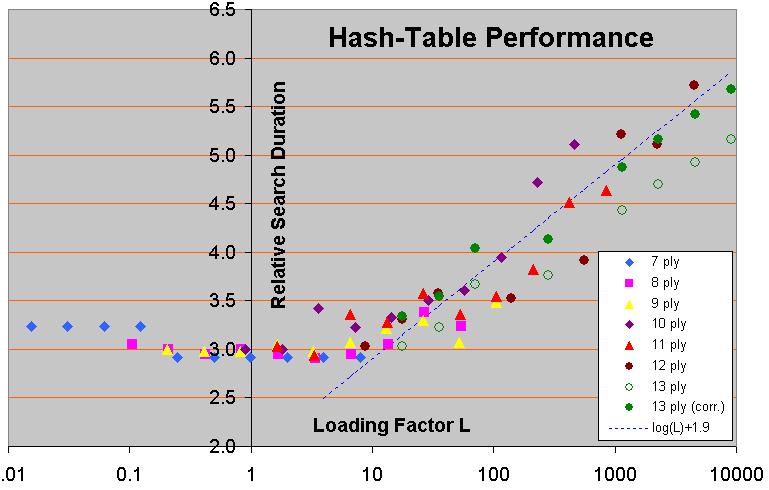
Effect of hash-table size on search time
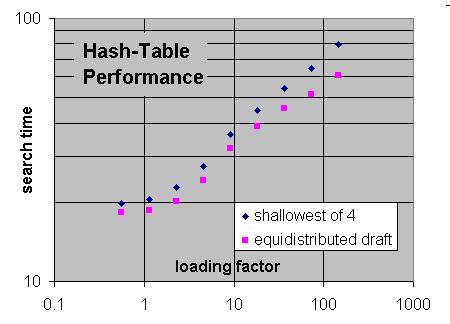
Performance comparison of two replacement schemes in perft (which is less noisy than search)
Also note that in equi-distributed draft there is no real need to purge the table of stale deep entries; these get overturned automatically if their number gets above their fair share in the table. E.g. if you typically search upto depth 20, each draft can at most occupy 5% of the table. Because the number of entries produced by the search decreases exponentially with draft, the drafts that do not reach this level (and thus would be never replaced) are dominated by the lowest draft that does not reach this level, even higher drafts being quite negligible in numbers. That means that only 5-8% of the table can be filled with drafts that get never replaced, and waste tablespace when they get stale, as opposed to 75% in shallowest-of-four without aging. Considering how weak a function the search speed is of TT size, trying to cut down this 5-8% even further hardly would gain you anything.
Effect of hash-table size on search time
Performance comparison of two replacement schemes in perft (which is less noisy than search)
Also note that in equi-distributed draft there is no real need to purge the table of stale deep entries; these get overturned automatically if their number gets above their fair share in the table. E.g. if you typically search upto depth 20, each draft can at most occupy 5% of the table. Because the number of entries produced by the search decreases exponentially with draft, the drafts that do not reach this level (and thus would be never replaced) are dominated by the lowest draft that does not reach this level, even higher drafts being quite negligible in numbers. That means that only 5-8% of the table can be filled with drafts that get never replaced, and waste tablespace when they get stale, as opposed to 75% in shallowest-of-four without aging. Considering how weak a function the search speed is of TT size, trying to cut down this 5-8% even further hardly would gain you anything.
-
brtzsnr
- Posts: 433
- Joined: Fri Jan 16, 2015 4:02 pm
Re: Transposition Age Tutorial
There is another technique, without age, that I use: have two hash functions h1, h2. To fetch you test at h1 and then at h2. To write you first see if you can replace h1 using normal conditions (e.g. higher depth) if not the always replace h2.
This way the new item is always inserted and old entries are slowly evicted. The hit rate is about 38-40 on ECM. For reference the code to insert an entry looks like this.
This way the new item is always inserted and old entries are slowly evicted. The hit rate is about 38-40 on ECM. For reference the code to insert an entry looks like this.
Code: Select all
func (ht *HashTable) put(pos *Position, entry hashEntry) {
lock, key0, key1 := split(pos.Zobrist(), ht.mask)
entry.lock = lock
if e := &ht.table[key0]; e.lock == lock || e.kind == noEntry || e.depth+1 >= entry.depth {
ht.table[key0] = entry
} else {
ht.table[key1] = entry
}
}
zurichess - http://www.zurichess.xyz
-
bob
- Posts: 20943
- Joined: Mon Feb 27, 2006 7:30 pm
- Location: Birmingham, AL
Re: Transposition Age Tutorial
Here's a question: Suppose you use a bucket size of 4, which is typical although some are beginning to go with 8, using an 8 byte uber-compressed table entry (different topic). All four entries in that bucket represent the same draft, so how do you choose which one to replace? Age might be a usable alternative when draft alone isn't enough to break the tie. What if two entries in the table represent the same draft (which is over-populated and should cause a replacement). How do you choose which one? Again age might help. Overpopulated and produced by the previous search would be a better choice it would seem.hgm wrote:What tested best for me was equi-distributed-draft replacement: replacing the entry with the draft that already occurs the most in the transposition table, irrespective of age. You just keep an array of counters, one for every draft, and you look up in the array how many of each draft in the bucket are already in the the table, and pick the entry that occurs the most. I.e. pick based on max(occurrence[depth]) rather than min(depth). And then of course update the counters when you replace.D Sceviour wrote:That is what was intended by suggesting to overwrite the entry that has the largest variance from the current alpha/beta bounds. An entry that has a value very close to current bounds might be expected to be more recent, or more useful as a first try best move. Of course this is still conjecture, as it needs a practical test.
Bob Hyatt has also mentioned that this stuff has already been tested to death.
A poor-man's approximation of this is 'under-cut replacement': Map each position to a 'primary entry' in the bucket. Replace that entry with a probability the inverse of the branching factor if the draft is exactly one higher than that of the position you need to store ('under-cut). Otherwise replace the entry in the bucket with the lowest draft, if that draft is equal or smaller to that of the entry to store. If even that is higher, store in the 'always-replace' entry in the bucket. This drives over-represented drafts out of the table, as the more there are, the more often they will be undercut.
-
bob
- Posts: 20943
- Joined: Mon Feb 27, 2006 7:30 pm
- Location: Birmingham, AL
Re: Transposition Age Tutorial
I wasn't particularly suggesting that those were the ONLY available results. I also remembered your posts here about evenly distributed drafts and such. And there are probably other posts and papers that discuss other approaches. BTW the authors incorrectly attribute the two-table (depth-preferred and always store) as that was a Belle idea circa 1980 when Ken did the belle chess engine and needed something that did not look "loopy" since loops in hardware are not nice.
The old Belle approach still works quite well, but the "bucket brigade" seems better overall and certainly more consistent.
The old Belle approach still works quite well, but the "bucket brigade" seems better overall and certainly more consistent.
-
hgm
- Posts: 27794
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Transposition Age Tutorial
The point is that this is all pretty unlikely. If every draft occurs about equally often, and fills, say, 5% of the table, the probability that all 4 entries in a bucket have the same draft is 1 in 8,000.bob wrote:Here's a question: Suppose you use a bucket size of 4, which is typical although some are beginning to go with 8, using an 8 byte uber-compressed table entry (different topic). All four entries in that bucket represent the same draft, so how do you choose which one to replace? Age might be a usable alternative when draft alone isn't enough to break the tie. What if two entries in the table represent the same draft (which is over-populated and should cause a replacement). How do you choose which one? Again age might help. Overpopulated and produced by the previous search would be a better choice it would seem.
The drafts higher than a certain N are not yet 'saturated', i.e. they would occur less frequently than every draft below N, and in fact all drafts above N together would occur hardly more than any single draft below N, because the production rate decreases exponentially with draft. Each next higher draft, say, 3 times less than the previous one. So roughly each draft takes 1/(N+1.5) part of the table. But the exponential production rate also applies to the lower drafts. If draft N was produced enough to exactly hit the 1/(N+1.5) mark, draft N-1 would have been produced 3 times as much, so that 2/3 of it must already have been replaced. And draft N-3 already overloaded the table by a factor 27. So if you are at the 27th move of the game (excluding the opening moves) the amount of draft N-3 entries that can be held in the table corresponds to a single move. And for draft N-4 an entry would typically already have been 3 times overwritten before the current search completes.
So when N=20, the drafts 1-16 would basically all be from the current search. Even in draft 17 only about 1/e of the entries from a previous search would have survived. Only for drafts 18, 19 and 20 you would have a good chance that ther might be an stale entry around that you would preferably like to replace. But it is very unlikely that would be in the same bucket. And on a global scale you gain very little, just a bit more efficiency in 3 of the 20 drafts.