Hi all.
I noticed that while Stockfish (since the inception of the syzygy-branch) uses Syzygy Tablebases, it lacks the UCI option for, say, "Syzygy Cache". Is the lack of TB cache by design or is this an option somehow missed about?
Thanks for any input or fixes made.
Question on Stockfish and SyzygyCache UCI option
Moderators: hgm, Rebel, chrisw
-
syzygy
- Posts: 5557
- Joined: Tue Feb 28, 2012 11:56 pm
Re: Question on Stockfish and SyzygyCache UCI option
By design.
Whereas other implementations keep a cache of uncompressed blocks, my implementation decompresses single TB values on the fly.
Whereas other implementations keep a cache of uncompressed blocks, my implementation decompresses single TB values on the fly.
-
EN
- Posts: 30
- Joined: Sun Nov 30, 2014 2:21 am
Re: Question on Stockfish and SyzygyCache UCI option
Okay, thank you very much for your insight. Obviously, I missed out on this critical information relative to the Syzygy bases/decompression.syzygy wrote:By design.
Whereas other implementations keep a cache of uncompressed blocks, my implementation decompresses single TB values on the fly.
-
Zenmastur
- Posts: 919
- Joined: Sat May 31, 2014 8:28 am
Re: Question on Stockfish and SyzygyCache UCI option
I'm kind of curious about how this is done.syzygy wrote:By design.
Whereas other implementations keep a cache of uncompressed blocks, my implementation decompresses single TB values on the fly.
I've been looking at different compression algorithms for table bases. I want to keep the database compressed while its being generated and I want a high compression ratio relatively speaking. Primarily because I can't keep it in memory since the files are too large. Normally a high compression ratio means a large dictionary or other large block of information about the file is gathered after it's created.
Since the files aren't complete yet, I was thinking about making a dictionary from a large group of representative files, then using that as a dictionary for all the EGTB using LZMA. In this particular case ALL the TB's will have pawns. After looking at statistical data for a TB worth of these it seems like it should work well enough. There are two drawbacks to this method. The first is that better compression could be had if the dictionary pertained to that specific file. I don't think this will be that much of a problem. My goal is to get significantly better than 3.4 to 1 ratios which is what I get using Microsoft drive compression. Simple tests show that between 16 and 20 to 1 compression ratios are possible with modest resources using 16 MB dictionary and compressing the whole file as a single block. With a 2 MB dictionary this drops to between 13 and 16 to 1.
The compression rate is between 28-40 MB's a second on a single core. Decompression rates are 200+ MB/second. Both of these seem adequate since the generation speed rarely runs faster than 14 MBs a second on my system. The other draw back is that the compression must be done in blocks. It would of course be better if individual values could be extracted with out decompressing a large block of data.
Most compression algorithms depend on blocks of data being compressed and decompressed which adds significantly to the overhead if you only need a single value from that block of data.
So I'm interested in how this is done. I've read a couple of papers that I though pertained to how you compressed these files, but now I'm not sure since I don't recall them mentioning being able to decompress a single entry.
Regards,
Forrest
Only 2 defining forces have ever offered to die for you.....Jesus Christ and the American Soldier. One died for your soul, the other for your freedom.
-
hgm

- Posts: 27790
- Joined: Fri Mar 10, 2006 10:06 am
- Location: Amsterdam
- Full name: H G Muller
Re: Question on Stockfish and SyzygyCache UCI option
When I designed my 7-men EGT generator I came to the conclusion that it was better to not use the same storage method for the finished tablebase and for the intermediate steps. The only info you are interested in during generation is which positions are won (with white to move), and which positions were declared lost (with black to move). These can be represented by bitmaps, and the latter bitmap is sparse to very sparse, so run-length encoding gives a very efficient compression.
EGTs with Pawns are usually very easy to keep in memory during building, as they factorize into much smaller P-slices.
EGTs with Pawns are usually very easy to keep in memory during building, as they factorize into much smaller P-slices.
-
syzygy
- Posts: 5557
- Joined: Tue Feb 28, 2012 11:56 pm
Re: Question on Stockfish and SyzygyCache UCI option
See the code and these posts:Zenmastur wrote:I'm kind of curious about how this is done.
http://talkchess.com/forum/viewtopic.ph ... 645#514645
http://talkchess.com/forum/viewtopic.ph ... 468#538468
The generator does not use this compression scheme. First the table is generated with a stupid fast indexing scheme. Then the table data is permuted to fit in a smaller index range and in an order that compresses best (according to estimations based on samples from the data). Then the permuted data is compressed into relatively small blocks that fit in a cache line. When probing these blocks are decoded (but not fully decompressed) until the value is obtained that is needed.
-
Zenmastur
- Posts: 919
- Joined: Sat May 31, 2014 8:28 am
Re: Question on Stockfish and SyzygyCache UCI option
It will take me a couple of days to digest the info on the page you link. I hadn't seen these before, even though I have browsed your sit several times.
Thanks and regards,
Forrest
Thanks and regards,
Forrest
Only 2 defining forces have ever offered to die for you.....Jesus Christ and the American Soldier. One died for your soul, the other for your freedom.
-
Zenmastur
- Posts: 919
- Joined: Sat May 31, 2014 8:28 am
Re: Question on Stockfish and SyzygyCache UCI option
syzygy wrote:See the code and these posts:Zenmastur wrote:I'm kind of curious about how this is done.
http://talkchess.com/forum/viewtopic.ph ... 645#514645
http://talkchess.com/forum/viewtopic.ph ... 468#538468
The generator does not use this compression scheme. First the table is generated with a stupid fast indexing scheme. Then the table data is permuted to fit in a smaller index range and in an order that compresses best (according to estimations based on samples from the data). Then the permuted data is compressed into relatively small blocks that fit in a cache line. When probing these blocks are decoded (but not fully decompressed) until the value is obtained that is needed.
Ah... So maybe I do know how they are compressed! I think I read the papers describing the compression technique. I'll have to go look at them again. In the mean time I looked at the syzygy from a statistical point of view and couldn't help but notice the compression didn't do that great of a job. I don't know what compression ratio your getting but it looks like it's possible to compress the files another 25-40%. Of course if this were done you wouldn't be able to decompress individual values, so its probably not a good trade off for general use.
Thanks for links.
Regards,
Forrest
Only 2 defining forces have ever offered to die for you.....Jesus Christ and the American Soldier. One died for your soul, the other for your freedom.
-
syzygy
- Posts: 5557
- Joined: Tue Feb 28, 2012 11:56 pm
Re: Question on Stockfish and SyzygyCache UCI option
I'm sure you haven't tested on the bigger files (the ones that matter).Zenmastur wrote:I don't know what compression ratio your getting but it looks like it's possible to compress the files another 25-40%.
Since I limit the compression to 65536 values per 64-byte block, the most highly compressible tables can probably be compressed further. But the bigger tables are 98% or so random data for any general purpose compresser (only the index tables can be compressed a bit). Those are the tables that matter. Try it.
-
Zenmastur
- Posts: 919
- Joined: Sat May 31, 2014 8:28 am
Re: Question on Stockfish and SyzygyCache UCI option
I didn't actually test it on any of your files since I don't have uncompressed versions of them, but the statistics I was looking at came from KRBvsKBP.RTBZ which is one of the largest file. I also checked some of the smaller files.syzygy wrote:I'm sure you haven't tested on the bigger files (the ones that matter).Zenmastur wrote:I don't know what compression ratio your getting but it looks like it's possible to compress the files another 25-40%.
Since I limit the compression to 65536 values per 64-byte block, the most highly compressible tables can probably be compressed further. But the bigger tables are 98% or so random data for any general purpose compresser (only the index tables can be compressed a bit). Those are the tables that matter. Try it.
Normalized byte counts for this file looks like this:
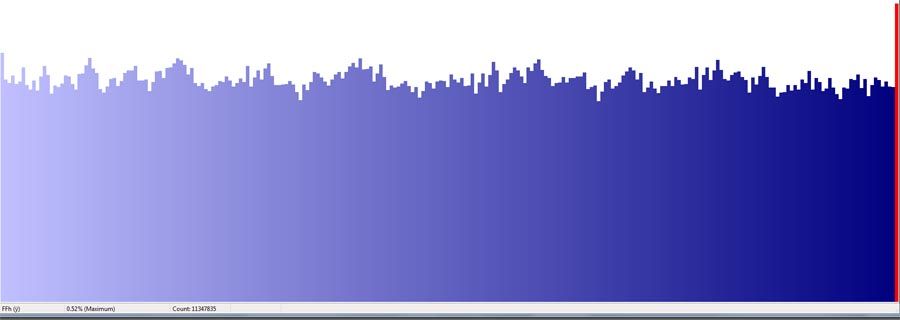
For comparison these are the normalized byte counts for one of the files I'm working with in uncompressed and after compression:


Notice the very uniform byte distribution in the compressed version of this file. There are other more sophisticated ways to look at the data but if this simple test show non-uniform byte distribution then there is still entropy in the file.
I agree that trying to compress an already compressed file isn't going to get you much. So, I'm not trying to imply that already compressed files can be compress significantly more. What I'm saying is that a statistical analysis of the files show considerable entropy still in the file. From previous experience I know that if a better compression method is used at the outset, additional compression can be achieved. I doubt that this would be worthwhile for the SYZYGY files because as I already mentioned it wouldn't allow single entry decompression, only relatively large blocks.
For my purposes it would GREATLY speed up the generation process if I could achieve good compression AND be able to decompress single entries. It would save tons of time on disk IO. My question is how much compression do I have to give up to get this ability.
A couple of questions for you:
1.) What compression ratio does the method you use achieve on the "average" EGTB file with pawns?
2.) If you take an uncompressed syzygy file, do what ever preprocessing you normally do and then compress it with a GP algorithm such as LZMA ( i.e. 7z using ultra option and LZMA) what's the compression ratio?
I've done this test on the files I'm generating and I get an average (with out any preprocessing) of about 20 to 1, best case around 33 to 1 and worst case around 16 to 1. This method is too slow for my purposes at about 3 MB/sec but its a good bench mark. Using LZMA with 2 or 4 MB dictionary I'm getting about 16 to 1 with worst case about 13.5 to 1 at 40 MB/sec which is an adequate speed for my purposes. If I could keep the compression above 12 to 1 and be able to decompress single quantities that would be GREAT!
In the mean time, I'll go over the links you gave previously.
Regards,
Forrest
P.S. I guess I don't know how to post pictures on this forum, but you can use the URL directly to see the images until I figure out how to get them imbedded.
Only 2 defining forces have ever offered to die for you.....Jesus Christ and the American Soldier. One died for your soul, the other for your freedom.