Laskos wrote:bob wrote:Laskos wrote:bob wrote:
Laskos wrote:
And after all your hard work you come with:
TTS (Time-To-Strength or Effective Speedup)=1 + (N-1) * 0.7
Where here is your "As far as "speedup depends on length of search" I believe _I_ am the first to point that out, in my DTS paper."? Your crap "formula" doesn't have appropriate asymptotic behavior and doesn't have the depth dependency for specific engines.
Then, TTD clearly is NOT an universal measure of TTS, whatever buggy "crocks" you consider some 3 of the top 6 programs. Buggy, too selective whatever, they seem to scale reasonably with the number of cores. You simply seem to have a mental rupture: if it cannot be, then it cannot be, although I see a bunch of them, it cannot be because it cannot be, nobody understands the parallel search, that's it.
"where is the depth part?" I simply tested deeply enough to get good numbers. How simple was that? SMP performance doesn't continue to improve for each ply you go deeper, it just improves until you get beyond the "noise" point.
As far as the rest goes, I simply understand the alpha/beta model. And I don't accept handwaving nonsensical explanations. And this "widening" is EXACTLY that. Nothing more, nothing less. Just like Vincent's old super-linear speedup nonsense. It happens, but NOT with any regularity. Any good book explains why.
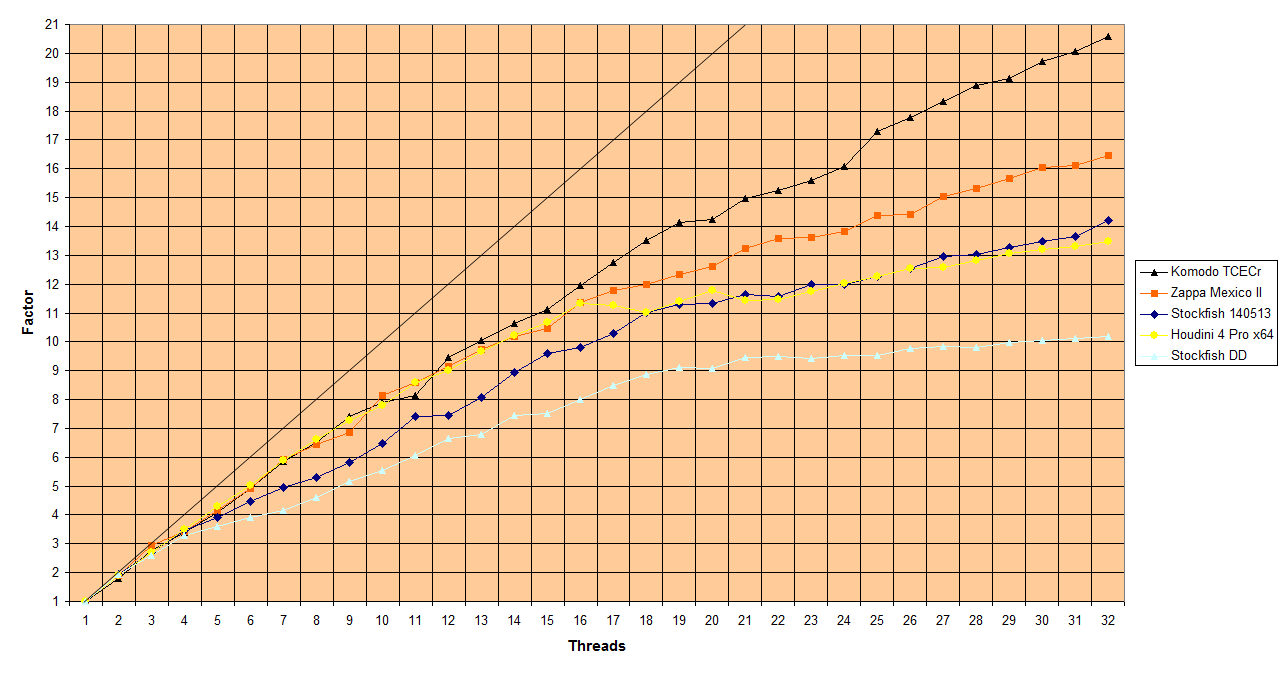
1) The dependence of depth is pretty significant even for high depths, so there is is none of your "deeply enough". There were posts here showing that. And it's not "noise", it's a monotonously increasing function with depth for speed-up.
2) The results presented here (lazy to dig them up) showed nothing of linear behavior for top engines to 32 cores. I was clearly some power function like 1+(N-1)^a or even logarithmic a+b*log(N). Maybe only DTS would work this linear way to 16 cores, although it surely won't work linearly to 2,000 cores, and no top engine uses DTS.
3) Isn't your linear crap formula 1 + (N-1) * 0.7 showing some weird behavior, that with each doubling the scaling improves? 2 -> 4 cores the doubling gives 1.82 in TTS, 16 -> 32 cores the doubling gives 1.97 in TTS. That's unreasonable, everybody knows (only you seem to miss it) that today's top engines don't gain much more than 1.4 (depends on depth too) in TTS going from 16 to 32 cores at reasonable depths.
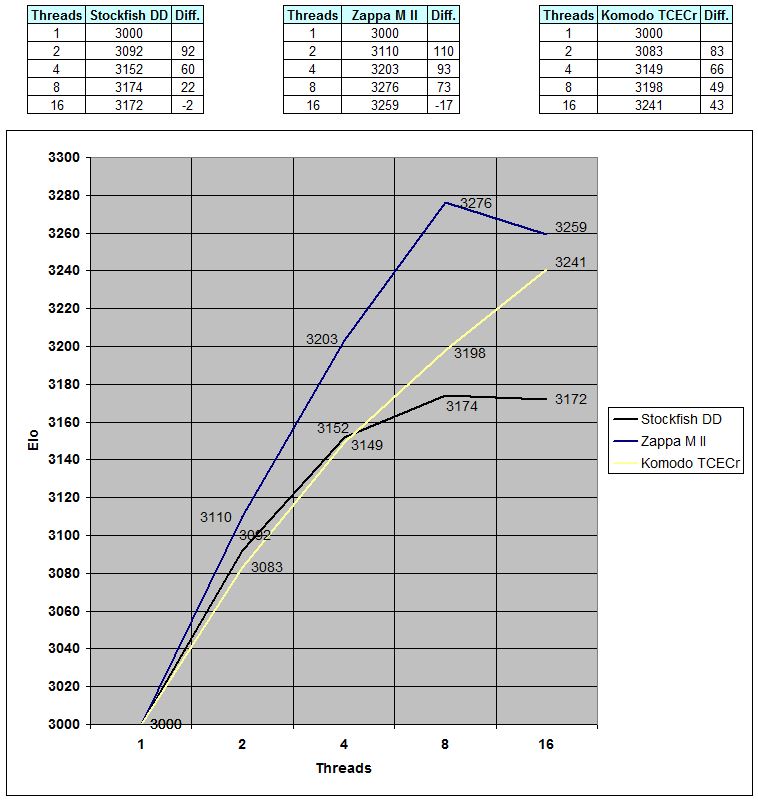
4) So, at least you admit that widening happens, maybe not with regularity, but with both of the top 2 engines, and with 3 of the top 6 engines. And TTD is for them a wrong substitute to the real TTS.
Don't know what you base the "no top engine uses DTS" on. Several HAVE reported to use DTS. Notably Zappa, but there have been others discussed here.
NOBODY has any sort of formula for 2000 cores, so you might as well get off that bandwagon, it is stuck in mud forever. Won't EVER be a shared memory machine with 2000 cores unless you venture into the old connection-machine architecture which did NOT scale very well for any parallel algorithm.
In short, my simple linear approximation is more than accurate enough for its intended purpose, namely to estimate the effective speedup / gain produced by some number of processors over a single one. It is not based on a few positions. It is based on hundreds of positions, run dozens to hundreds of times, to produce good averages.
I have NEVER said "widening does not happen." I have certainly said "it does NOT happen INTENTIONALLY". Because if widening improves a parallel search it will ALSO improve a serial search just as much. That is a trivial point once you think about it. Ergo, "widening" is an accidental thing that simply points out a defect in the basic search....
Zappa came 4th at 2006 WCCC on 512 Itanium2 processors, behind the likes of Shredder and Junior, which used 4 or 8 cores. If Zappa was using DTS, then it performed poorly. By your linear approximation, it should have been 350 Elo points above the competition. Anyway, I was saying that no present day top engine uses DTS.
Your linear approximation gives roughly the following series of Effective Speedup (TTS) per additional doubling (to 32 cores):
1.7, 1.8, 1.9, 1.95, 1.97
This is nonsensical, the scaling improves for each additional doubling.
A power series would give
1.7, 1.7, 1.7, 1.7, 1.7
What Vasik reported awhile ago on the Rybka Forum and what 32 core tests showed here recently was roughly:
1.8, 1.7, 1.6, 1.5, 1.4
This is consistent with diminishing value as TTS for each higher doubling. And is consistent with some sort of logarithmic scaling of the form 1+a*log(N), disregarding the depth dependency. And again, is consistent with what 512 or 2,000+ core machines have achieved.
My first suggestion is to PLEASE study computer architecture a bit. Do you have ANY idea what that Itanium box looks like in terms of architecture? NUMA. With MASSIVE memory latency issues. Comparing that to todays 12-16-24 core boxes is a waste of time.
You fail to mention that although the scaling doubles on out there, it is WAY below the optimal speedup.
better numbers
cores speedup speedup over previous test
2 1.7x -
4 3.1x 1.82
8 5.9x 1.90
16 11.5x 1.94
My formula is based on a lot of search overhead measurement, which may or may not be accurate today, I am going to test to reconfirm the numbers. But over hundreds of positions, searched dozens of times and averaged together, adding a second CPU searches nodes the serial search avoids by alpha/beta, because of incorrect internal bounds caused by sub-optimal move ordering. In general, if one CPU searches 100M nodes, two CPUs should search 50M nodes each for a perfect speedup. But actually each of the CPUs waste about 15% of its time because it adds extra nodes that the serial search would not search. So instead of searching 100M nodes with 2 cpus, we search 115M
The math goes like this.
1 cpu = 100M nodes at 1M nodes per second = 100 seconds.
2 cpus makes things more interesting. The typical speedup is around 1.7x=1.8x. I chose a pessimistic number to under-estimate rather than over-estimate. Since 2 cpus stay busy the whole time, but the speedup is not 2.0, something is going on. And that something is the search space is bigger. To get a perfect speedup both would search 100M nodes total, but in reality they end up searching something around 117M nodes. At 2M nodes per second, we get a search time of 58.5s and a speedup of 1.7x.
4 cpus continues that trend. The tree continues to grow each time another cpu is added, so that even if they all suffer no NPS reduction due to cache/memory conflicts, the search space increase eats up part of the NPS improvement by the additional cores.
You want to argue the statistical point that more processors approaches optimal. But that's a twisted view. optimal = number of processors.
I don't see anything that suggests my formula is broken, it simply suggests that as the number of processors grows, the actual workload (overhead) grows at a constant rate, which seems perfectly reasonable for a chess engine. That single CPU (before adding the others that bring in overhead) is slowly being averaged away because it is the perfect searcher and all the others add in overhead. Eventually the overhead becomes the limiting factor for speedup each time. But it is STILL well below the optimal speedup.
You are simply thinking about the numbers wrong, and it really does NOT make much sense to compute the speedup, then compute the speedup of the current value compared to the previous value. Since my linear approximation is a straight line, that equation is going to approach that line as N increases. I don't see anything theoretically pro or con the point of view that for larger numbers of processors the overhead continues to increase at a constant rate. What do you see that suggests otherwise. I wrote a paper for the journal of parallel computing about 25-30 years ago addressing this "overhead". And the math suggests that a constant increase as you add processors is perfectly reasonable, assuming nothing happens to cause move ordering to break down (which would certainly increase overhead.)
Think about it. If you plot
1, 1.7, 2.4, 3.1, 3.8, ... that 1 at the front was the ONLY whole number in the formula. I'd think a statistician would recognize that 1 + (N-1) * 0.7 approaches N * 0.7 as N gets large. Only issue is, does that 0.7 change. At least for reasonable N (1-16 for certain, some testing on the Cray C90/32 (32 cpus) stayed right in line with that) there's nothing to suddenly increase overhead, until something changes the tree in some important way. It becomes harder to use more CPUs as the tree grows, because if you have less than 32 moves at a ply, 32 cpus is not going to help. But you CAN split elsewhere, and that might well tend to decrease that .7 number by increasing overhead. But for the hardware I have tested on (1-16 HEAVILY and 1-32 less rigorously, and 1-64 minimally) that simple approximation does quite well. Somewhat pessimistic on the low end, "perhaps" somewhat optimistic beyond 32, and I would not make any claims beyond 32 since the 64 core testing I have done was minimal.
I suspect current hardware is not as good as what I used years ago, because when you take a single chip and build in 6 or 8 cores, you build in a bottleneck as well, as that L3 cache can't keep up with all of those cores, nor can a single memory bus handle the requests from all the cores either. On the first 8-cpu opteron box I ran on, my NPS scaling was perfect. It has dropped off over time as the number of cores per chip has climbed. That being said, the 3.1x for 4 seems to be somewhat pessimistic today, the last time I tested 1, 2 and 4 put the number north of 3.3x. But my formula was never intended to provide an exact (or nearly exact) speedup. In fact, no such number exists, because it varies based on hardware, chess position, memory used, etc. Giving a complex polynomial or exponential formula is not exactly useful when the question most ask is "about how much faster will 8 cores be over 4?" The linear approximation is quite simple to compute in your head, and it gives a number more than good enough when "speedup" is not a constant under any circumstances, anyway. It will never give the exact number, ever. It just gives a reasonable first-order approximation. Which is all most want. If you want exact numbers, run at least enough positions to hit all phases of the game, and run them enough times that the standard deviation is reasonable. For me, I use about 100 positions, and with 2 cpus I run 'em all 4 times. For 4 cpus I run em all 8 times, and for 8 cpus, I run em all 16 times. I run to a fixed depth, where the depth requires at LEAST 3 minutes with the max number of processors. That averages away the rather significant non-determinism one sees in parallel speedup on alpha/beta trees.
If you want to estimate the computational cost, for 8 cpus that is
16 runs * 100 positions * 3 mins_per_position = 3+ days.
Of course, you need to run the others. That 1 cpu test, assuming a 6x speedup for 8 turns into
1 run * 100 positions * 3 * 6 minutes = 1+ day. the 2 and 4 cpu tests will burn another 2-3 days. One week of nonstop testing. And then you get a pretty accurate "average speedup" that says absolutely nothing about a specific position.
BTW another flaw I saw in your analysis was that 32 core test you mentioned.
The proper test method:
1. run a single cpu test to establish NPS.
2. run a max cpu test and take NPS.
The NPS from 2 divided by the NPS from 1 gives you a max speedup before you even START to factor in my "formula". If a 12 core box won't provide 12x the NPS, then it is impossible for it to provide a 12x speedup if the software algorithm was perfect.
Other than the 32 CPU cray (which has NO memory bottlenecks BTW) I have not seen any machine recently where a program scales perfectly. More cores and more local/shared caches add their own overhead to the equation that is outside the software being tested.
On my 2x6core cluster, a single core runs crafty at 4.9M nodes per second (this is 4 year old hardware, not particularly fast). On this particular position, it settles into the 4.9M number after 10 seconds or so and sticks there beyond 2 minutes. For 12 cores, Crafty settles right at 46M nodes per second, same position. An effective scaling of 9.38x. My parallel speedup on this box can never exceed 9.38x, even if the parallel search is perfect and has no overhead (impossible, obviously). My formula is off here, unless you correct for the above problem, and instead of calling this a 12 core box, call it a 9.4 core box, and suddenly it is right back in the right ballpark again...